11.6 Application Programming Interfaces
Application programming interfaces (APIs) are tools that allow you to search a large database to extract specific types of information. Social scientists often work with APIs to extract data from social media platforms, government agencies (e.g., U.S. Census), and news sites, among others.
Organizations that develop these APIs can control what types of information researchers can access. Often, they set limits on the types and quantities of information someone can collect. Companies also often monitor who accesses the information by requiring people to sign up for access, apply for access, and/or pay for access.
Example: Census API As an example of an API, the U.S. Census has an API that allows researchers to extract nicely formatted data summaries of different geographic units (e.g., all zip codes in the U.S.).
- Researchers can sign up here for an API “key” which allows the organization to monitor who is accessing what information.
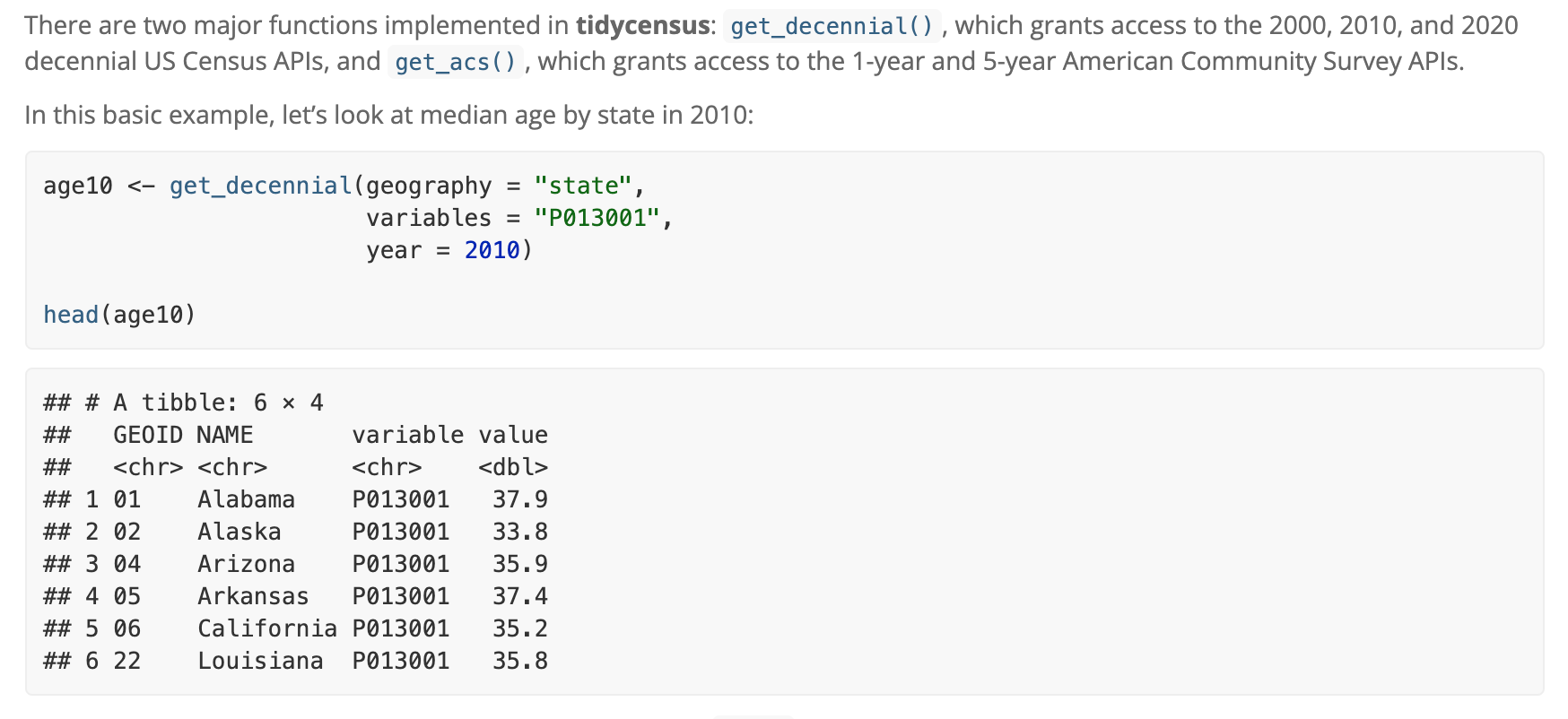
Researchers Kyle Walker and Matt Herman have made an R package that makes working with the API easier.
- Example:
tidycensusfound here allows you to search Census data by providing the variables you want to extract
APIs can make a social scientist’s life easier by providing an efficient way to collect data. Without an API, researchers might have to resort to manually extracting information from online or writing an ad hoc set of code to “scrape” the information off of websites. This can be time consuming, against an organization or company’s policy, or even impossible in some cases. APIs are powerful and efficient.
However, because researchers cannot control the API, the downside is at any given time, an organization could change or remove API access. Researchers might also not have the full details of what information is included in the API, potentially leading to biased conclusions from the data. APIs are great, but we should use them with caution.
Because the APIs require you to sign up for access (giving away your information), this course will not require that you gain access or use the APIs
11.6.1 Twitter API v1
Let’s try an example working with a Twitter API. To use this version of the Twitter API with R, you need
- To create a Twitter account (you don’t need to tweet from the account, just need an account)
- An internet connection
- To install the
rtweetpackage
install.packages("rtweet")Let’s open the package
library(rtweet)The API sets guidelines about what and how much information a person can collect from Twitter over a particular duration of time. With the version of the API we are working with, we can collect a few thousand of the most recent tweets of any public user and search recent tweets (past few days) on Twitter that include keywords.
- Twitter has other versions of the API that academic researchers can apply to for broader access, including access to older tweets (e.g., if you wanted to study tweets during the 2020 election). Researchers have developed a separate R package for working with this broader API.
11.6.1.1 Searching tweets for keywords.
The first time you use a function from rtweet, R will prompt you to authenticate and authorize an “app” through your Twitter account. Essentially, a web browser on your computer should automatically open to a Twitter landing page asking you to hit the “authorize” button. Once you do this, then you should be able to return to R and work with the R functions. (This is why you need a Twitter account and an internet connection to work with this package.)
We can use the search_tweets function to search recent tweets that contain keywords. We can specify the number of tweets to extract with the n argument. We can also filter tweets with additional arguments, such as by limiting tweets to English tweets or omitting retweets.
## simple keyword search
taylortweets <-search_tweets("taylorsversion", n=1000)
## use ' ' to search for exact phrase
simmonstweets <-search_tweets('"ben simmons"', n=1000)
## use OR between words to search for tweets with at least one of the key words
f1tweets <- search_tweets('"daniel ricciardo" OR "lando norris"', n=500)
## just keep a space between words, no extra quotes to search for tweets that include both words somewhere
bachtweets <- search_tweets("bachelorette michelle", n=400)
## limit tweets to include only english tweets
coronatweets <- search_tweets("coronavirus OR COVID", n=200, lang = "en")
## omit retweets, may affect total n extracted
rittenhousetweets <- search_tweets("rittenhouse", n=200, include_rts = FALSE)The resulting object we created with the first search, taylortweets, is a dataframe and includes the 1000 tweets we requested to extract along with 90 variables of information about those tweets. A few notable variables:
screen_name: the screen name of the twitter usertext: the text of the tweetis_retweet: an indiactor TRUE or FALSE indicating if the tweet was a retweetfavorite_count: the number of times the tweet was favorited (liked)followers_count: number of followers the user hasfriends_count: number of users that the tweeter followsstatuses_count: the number of tweets from the userverified: an indicator TRUE or FALSE indicating if the user is verifiedlang: language of the tweet
11.6.1.2 Extracting user timeline
Here is an example of extracting tweets from a particular user. You cane extract up to 3200 recent tweets of a specified public user. If you try to extract tweets from several users at once, you might hit a “rate limit” indicating that you requested more information than allowed over a particular period of time.
## extracting tweets from potus
bidentweets <- get_timeline("potus", n=3200)
## extracting tweets from potus
polleaders <- c("potus", "vp")
poltweets <- get_timeline(polleaders, n=3200)Similar to the keyword tweets, the object created will provide the text of the tweets and information about the reactions to the tweets.
11.6.2 Saving R Objects
After you extract an tweets from online, you may want to save them as a hard data file on your computer. This way if you close RStudio, you can recover the tweets without needing to extract new tweets from Twitter.
R allows you to save any R object as an .RData file that can be opened with the load() command. This is discussed on pg. 24 of QSS Chapter 1.
We can demonstrate this now by saving taylortweets as an RData object. It will automatically save to your working directory, but you can also add a subfolder or alternative file path.
save(taylortweets, file = "taylortweets.RData")Prior to saving the file, you could consider limiting the number of variables you want to save if you didn’t want to store 90 variables. Example of keeping only 5 variables:
taylortweets <- taylortweets[, c("user_id", "screen_name", "text", "created_at", "is_retweet")]
save(taylortweets, file = "taylortweets.RData")Then, you can load the file (if you happen to close R/RStudio, restart your computer, etc.) with the load command.
load("taylortweets.RData")