15.2 In-sample vs. Out-of-Sample
Problem: Models that fit our existing (“in-sample”) data might not be the best for predicting out-of-sample data. Issues with variability and overfitting.
- There may be idiosyncratic features of the data for which we do know the ground truth (e.g., outliers, different levels of variability) that could lead to poor predictions. This can lead to overfitting– predicting your particular dataset reaaaaaallly well, but any other data, more poorly.
- Our training data could be unrepresentative of the population in some way
For example, many AI tools suffer from gender and/or racial biases due to unrepresentative training data. If most of the data used to train a speech detection or facial recognition tool was trained on white faces/ white voices, it may have poor accuracy for other groups.
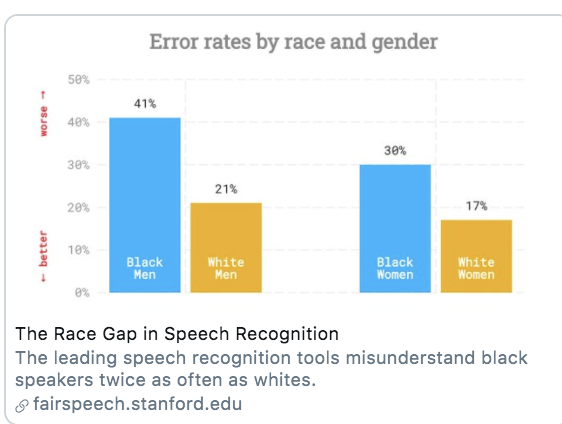
Solutions:
- Choose your training data wisely!
- Search for systematic biases along key variables (instead of aggregate accuracy, also look for accuracy measures by subgroups)
- Use out-of-sample predictions/classification tests to help avoid overfitting
- Split data into train vs. test and/or do this repeatedly with
- Cross-validation