basque <- read.csv("basque.csv", stringsAsFactors = T)6 Loops in R
In this brief section, we will go over conducting loops in R.
Loops are a tool in R that are useful for situations where we want to do something over and over and over and … over again, where we just change something small each time.
A quick example using the Basque data from the previous section:
Let’s say I wanted to know the GDP for each region for the earliest year they are in the data.
regionsubset <- subset(basque, region == "Andalucia")
regionsubset$gdpcap[regionsubset$year == min(regionsubset$year)][1] 1.688732## Repeat for a new region
regionsubset <- subset(basque, region == "Aragon")
regionsubset$gdpcap[regionsubset$year == min(regionsubset$year)][1] 2.288775## Repeat for a new region
regionsubset <- subset(basque, region == "Baleares")
regionsubset$gdpcap[regionsubset$year == min(regionsubset$year)][1] 3.143959Ughhh can we automate this? we have 17 regions!!!
unique(basque$region) [1] Andalucia Aragon Principado De Asturias
[4] Baleares Canarias Cantabria
[7] Castilla Y Leon Castilla-La Mancha Cataluna
[10] Comunidad Valenciana Extremadura Galicia
[13] Madrid Murcia Navarra
[16] Basque Country Rioja
17 Levels: Andalucia Aragon Baleares Basque Country Canarias ... RiojaWhere we will be going by the end of this section:
gdpminyear <- rep(NA, 17) # empty "container" vector
regions <- unique(basque$region) # what we iterate through
names(gdpminyear) <- unique(basque$region) # labels for our output
for(i in 1:17){
regionsubset <- subset(basque, region == regions[i])
gdpminyear[i] <- regionsubset$gdpcap[regionsubset$year ==
min(regionsubset$year)]
}
head(gdpminyear) # output Andalucia Aragon Principado De Asturias
1.688732 2.288775 2.502928
Baleares Canarias Cantabria
3.143959 1.914382 2.559412 We got all of the answers with just one chunk of code!
6.1 The anatomy of a loop
A short video introduction to the anatomy of a loop
In many situations, we want to repeat the same calculations with different inputs. Loops allow you to avoid writing many similar code chunks.
- The function
for(i in X){}}will create a loop in your programming code whereiis a counter and Xis a placeholder for a vector for the possible values of the counter.
We use the following syntax:
for (i in X) {
command1...
command2...
...
}
to indicate we want to repeat command1 and command2 and …. as many commands as we want, for each i in the set of possible values for i stored in X.
6.1.1 The key parts of a loop
The meat: the command or set of commands you want to do over and over.
## the meat
result <- 6 + 2
result <- 8 + 2
result <- 4 + 2
result <- 7 + 2
result <- 11 + 2Note the pattern: we take some number and + 2 each time.
- It is the number that is changing -> what we will iterate.
For a loop, you want to:
- The Meat: Write down the code for one version.
result <- 6 + 2- The Bread: Embed this code in the loop syntax (
for(i in X){})
for(i in X){
result <- 6 + 2
}- Create a vector that contains the values you want to loop through
somenumbers <- c(6, 8, 4, 7, 11)- Create a storage vector that will contain the results
result <- rep(NA, length(somenumbers))- Modify the meat and bread to iterate by using
[i], and replaceX.
for(i in 1:length(somenumbers)){
result[i] <- somenumbers[i] + 2
} where `1:length(somenumbers)` reflects possible values `i` will take 1:length(somenumbers)[1] 1 2 3 4 56.1.2 A short example
Let’s put these parts together:
Suppose we want to add 2 to a set of numbers c(6, 8, 4, 7, 11)
somenumbers <- c(6, 8, 4, 7, 11) # iteration vector
result <- rep(NA, length(somenumbers)) # container vector
for(i in 1:length(somenumbers)){
result[i] <- somenumbers[i] + 2
}
result[1] 8 10 6 9 13How does this work? Every iteration, the value of i changes.
- For example, when
iis 1, we take the first value in oursomenumbersvectorsomenumbers[1], add 2 to it, and store it in the first position of our container vectorresult[1]. Wheniis 2, we switch the number in the brackets to 2, corresponding to the second entry in each vector, and so on.
# Suppose i is 1
result[1] <- somenumbers[1] + 2
result[1][1] 8# Suppose i is 2
result[2] <- somenumbers[2] + 2
result[2][1] 10# Suppose i is 3
result[3] <- somenumbers[3] + 2
result[3][1] 66.1.3 Troubleshooting a loop
The inside part of the loop should run if we set i to a particular value.
i <- 1
result[i] <- somenumbers[i] + 2If you get an error here, there is something wrong with the meat! (and not necessarily the loop)
result[i][1] 8For example, if we had a typo, we’d get an error. Try running the below!
i <- 1
result[i] <- somenumberz[i] + 26.1.4 Your turn
Using a loop, for each value in our poll results, add 10 and divide by 100. Store in a vector called adjustedpollresults.
pollresults <- c(70, 40, 45, 60, 43, 80, 23)Remember the steps:
- The Meat: Write down the code for one version.
- The Bread: Embed this code in the loop syntax (
for(i in X){}) - Create a vector that contains the values you want to loop through (here it’s
pollresults) - Create a storage vector that will contain the results (here it’s
adjustedpollresults) - Modify the meat and bread to iterate by using
[i]and replaceX.
Try on your own, then expand for the solution.
pollresults <- c(70, 40, 45, 60, 43, 80, 23)
adjustedpollresults <- rep(NA, length(pollresults))
for(i in 1:length(pollresults)){
adjustedpollresults[i] <- (pollresults[i] + 10)/100
}
adjustedpollresults[1] 0.80 0.50 0.55 0.70 0.53 0.90 0.336.2 Application: U.S. Supreme Court
A video explainer of the loop in this section using a similar dataset that goes through 2020. We now have data going through 2021!
The Court has changed a lot recently in its composition (and will continue to do so next term).



Ideology on the U.S. Supreme Court: With Kennedy out, Kavanaugh in, did the Court have a Conservative shift? What about with the death of Ruth Bader Ginsburg and confirmation of Amy Coney Barrett?
Many people predicted it would. See this FiveThirtyEight article as an example. The graph from the article shows Kavanaugh’s predicted ideology.

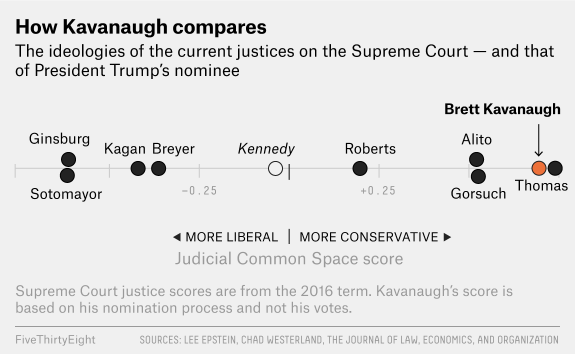
We will explore how the Court has changed ideologically, with a focus on how the location of the median U.S. Supreme Court Justice shifted over time.
Why does the median matter? A refresher on the Court
- President nominates the justice. Senate must confirm.
- Justices serve lifetime appointments.
- Trump nominated Gorsuch, following Scalia death, confirmed 2017.
- Trump nominated Kavanaugh, following Kennedy retirement, confirmed 2018.
- The Court typically has 9 justices, so whichever justice is the median in terms of ideology, can act as the “swing” vote in cases where the Court is divided
- Anthony Kennedy was often the “swing” justice for a decade.
- With Kennedy out, the prediction was that the Court would return to similar balance as when O’Connor was the median.
- In 2020, Ruth Bader Ginsburg died and Amy Coney Barrett was confirmed to Court late that year, likely shifting the Court again.
- We can continue to update the data to examine what happened. We don’t yet have data on changes to the Court that have come about since Justice Ketanji Brown Jackson was confirmed following the retirement of Justice Breyer.
Let’s load and explore our data.
term: is the year of the SC (1991-2021 except for 2005),justiceName: contains the name of the Justice, and
post_mn: includes the “ideal point”– this is the estimated ideology
Martin-Quinn Scores assess ideology based on how judges “cluster” together in their voting patterns. Every Justice gets an ideology score, and this score can change each SC term (year) they are on the Court. Higher scores are more conservative justices, and lower, more liberal. More information is available at the MQScores website
justices <- read.csv("justices23.csv", stringsAsFactors = T)
## alternative
justices <- read.csv("https://raw.githubusercontent.com/ktmccabe/teachingdata/main/justices23.csv", stringsAsFactors = T)We are going to make the name variable a character class. This will make R treat the names as raw text rather than valued categories. This will be useful later on in the application.
## justice Name as character
justices$justiceName <- as.character(justices$justiceName)We can use tapply() to see the median “ideal point” (ideology score) each term in our data.
## Note: we use tapply like before but replace mean with median
medians <- tapply(justices$post_mn, justices$term, median)
plot(x =names(medians),
y= medians,
ylim = c(-.4, 1),
type = "b",
cex=1.5,
ylab="Conservatism",
xlab="Term",
main="Median of US Supreme Court over Time")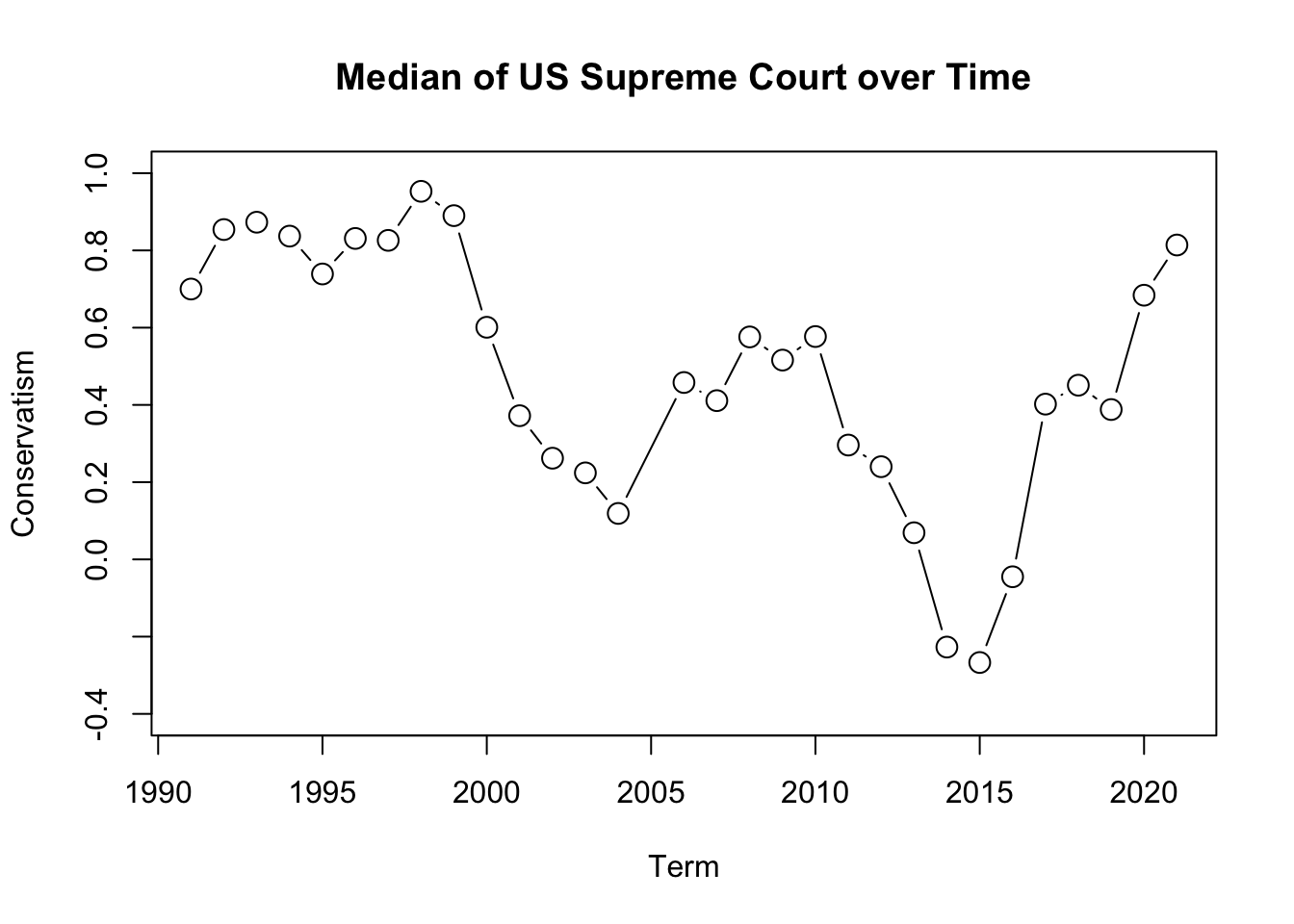
We see a conservative shift at the end of the plot. However, we cannot tell whether this represents a shift within a particular justice’s ideology or a shift in which justice has become the median, due perhaps, to the change in the Court’s composition.
We need to find which justice is the median!
Loops to the rescue!
We will start our process by defining the meat of the operation.
- We want to find the median SC Justice for each term. To get started, let’s pretend we only have to find the median Supreme Court Justice for one term.
SCterms <- sort(unique(justices$term))
SCterms [1] 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2006
[16] 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 2021Note that where you have a vector where some entries in the vector are repeated (such as terms on the Supreme Court), you can extract the unique elements of that vector using the unique() function. You can also sort() them in numeric or alphabetical order. This won’t be necessary most times.
First, let’s think about how we would do this for just one of the Supreme Court terms. Well we would first subset our data frame to contain only that one Supreme Court term.
## Example for the first term
SCterms[1][1] 1991## Subset data to include only rows from 1991
subterm <- subset(justices, term == 1991)Then, we would take the median of these ideal points
median.ip <- median(subterm$post_mn)Finally, we would figure out which justice has this median.
result <- subterm$justiceName[subterm$post_mn == median.ip]
result[1] "SDOConnor"Now let’s put it into our loop syntax
# for(i in . . . ){
# subterm <- subset(justices, term == 1991)
# median.ip <- median(subterm$post_mn)
# result <- subterm$justiceName[subterm$post_mn == median.ip]
#}Now, we need our container vector and iteration vectors.
SCterms <- sort(unique(justices$term))
results <- rep(NA, length(SCterms))
names(results) <- SCtermsFinally, we would modify our loop syntax with i and [i]
for(i in 1:length(SCterms)){
subterm <- subset(justices, term == SCterms[i])
median.ip <- median(subterm$post_mn)
results[i] <- subterm$justiceName[subterm$post_mn == median.ip]
}Did it work?
results 1991 1992 1993 1994 1995
"SDOConnor" "SDOConnor" "AMKennedy" "SDOConnor" "AMKennedy"
1996 1997 1998 1999 2000
"AMKennedy" "AMKennedy" "AMKennedy" "SDOConnor" "SDOConnor"
2001 2002 2003 2004 2006
"SDOConnor" "SDOConnor" "SDOConnor" "SDOConnor" "AMKennedy"
2007 2008 2009 2010 2011
"AMKennedy" "AMKennedy" "AMKennedy" "AMKennedy" "AMKennedy"
2012 2013 2014 2015 2016
"AMKennedy" "AMKennedy" "AMKennedy" "AMKennedy" "AMKennedy"
2017 2018 2019 2020 2021
"AMKennedy" "JGRoberts" "JGRoberts" "BMKavanaugh" "BMKavanaugh" Our evidence aligns with others:
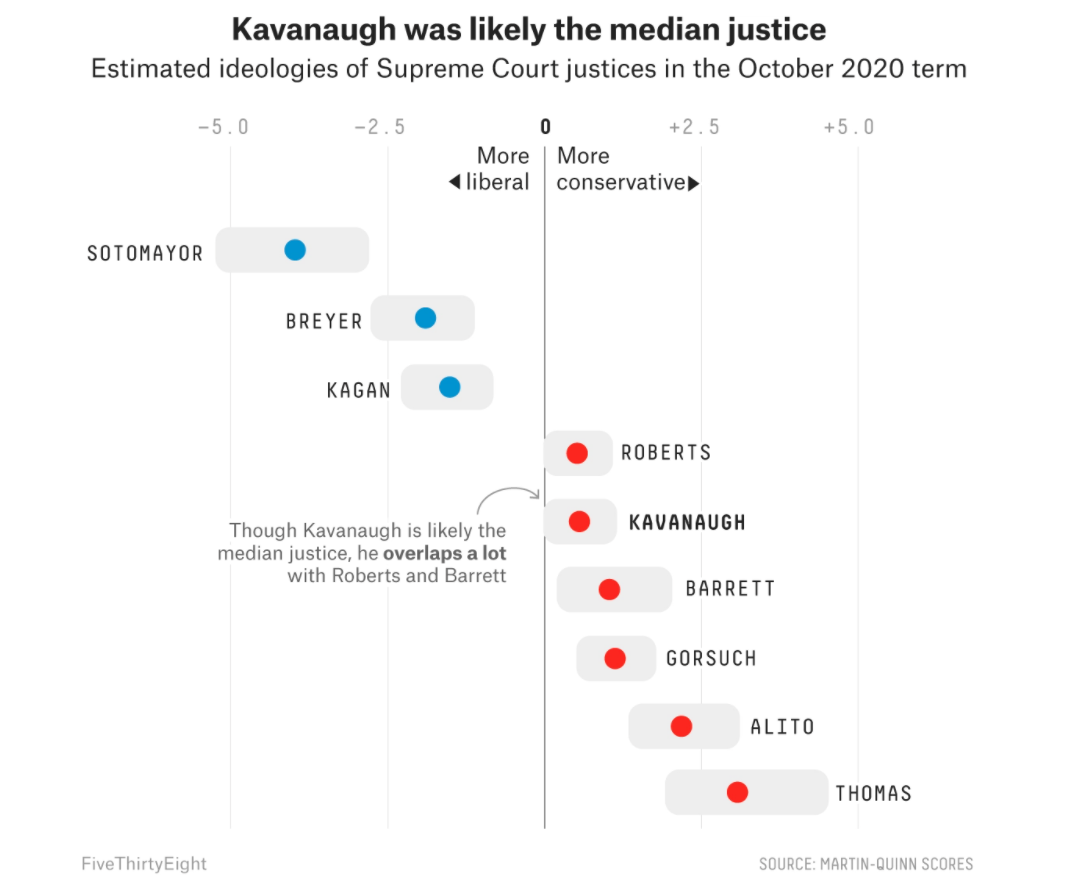
6.2.1 Troubleshooting the loop
Recall, the inside part of the loop should run if we set i to a particular value.
i <- 1
subterm <- subset(justices, term == SCterms[i])
median.ip <- median(subterm$post_mn)
results[i] <- subterm$justiceName[subterm$post_mn == median.ip]
results[i] 1991
"SDOConnor" We are in good shape! If we had a typo, we’d get an error message there, and that would be a sign that we need to work on the inside part of the code before putting it back into the loop structure.
6.2.2 Visualizing the Results
To get a bit more practice with plots, let’s visualize the results and make our interpretations.
medians <- tapply(justices$post_mn, justices$term, median)
plot(x =names(medians),
y= medians,
ylim = c(-.4, 1),
type = "b",
cex=1.5,
ylab="Conservatism",
xlab="Term",
main="Median of US Supreme Court over Time")
## Add the names to the plot
## Note: we want to make sure medians and results are in the same order for this to work
text(x=names(results), y=(medians - .14), labels=results, cex=.35)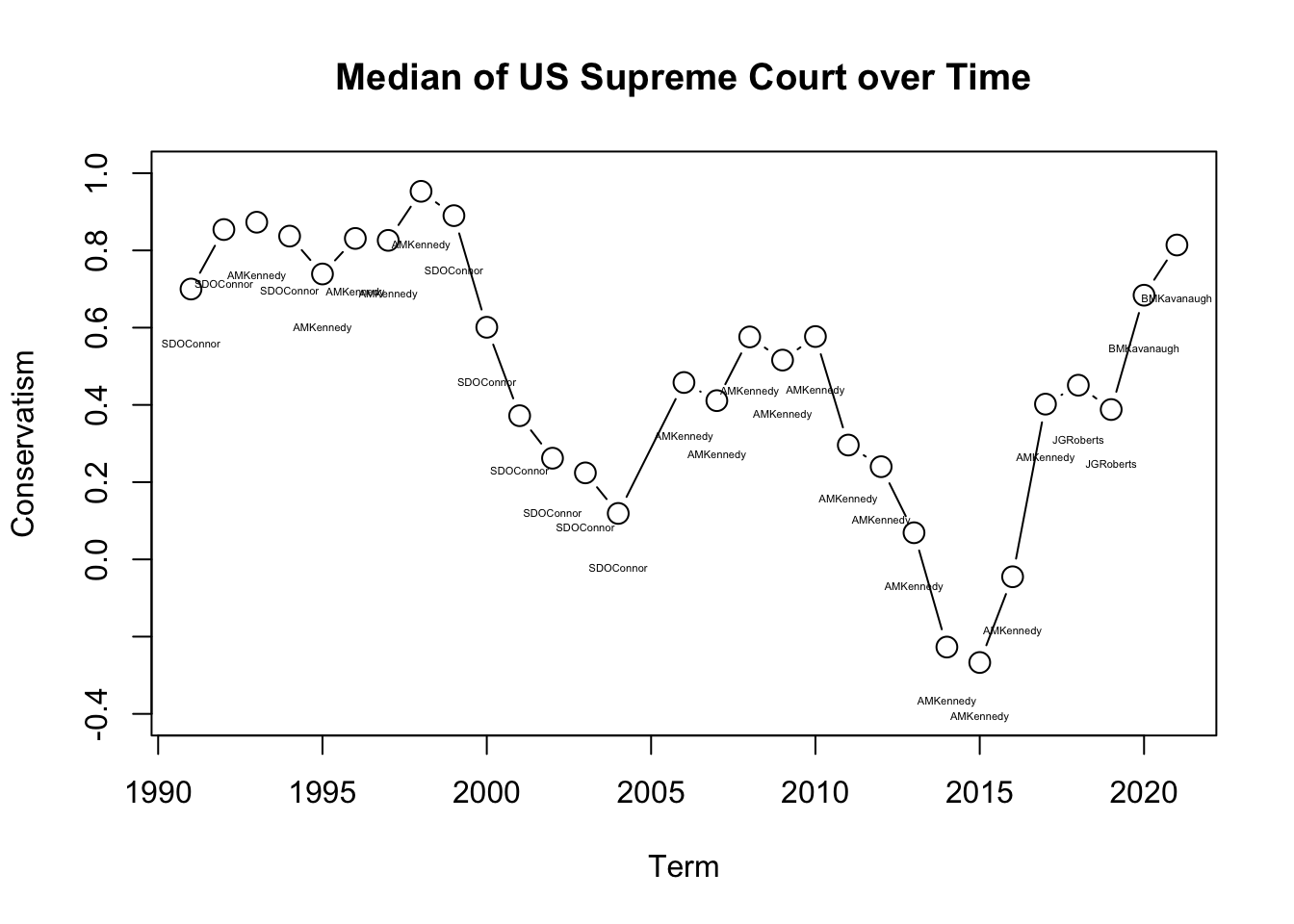
We have now used the text() function. Similar to plot, the text() takes a set of x and y coordinates that tells R the location of where you want to add a piece(s) of text to the plot. The third input is the actual text.
Why did the Court shift more conservative at the end of the time trend?
- Well we see that Justice Roberts and then Justice Kavanaugh became the median!
As FiveThirtyEight notes, just because Justice Roberts is the new median, does not mean he has become more liberal. The Court composition is shifting, and the MQ scores also depend on the issues being heard before the Court.
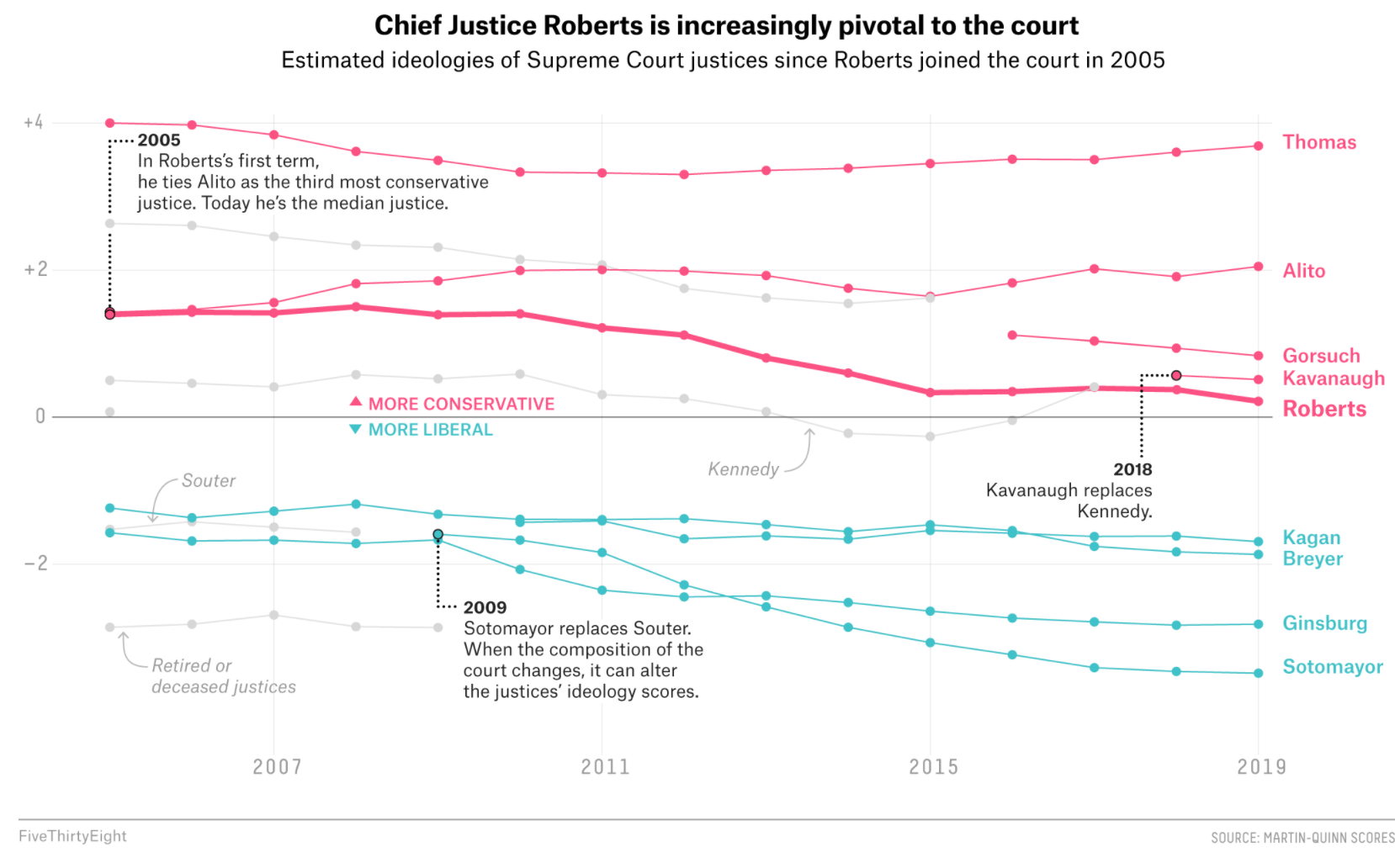
Recall, the Martin-Quinn scores measure justice ideology based on voting patterns. What are the strengths and weaknesses of using this type of information to score the ideology of a justice?
6.2.3 Enhancing the plot
Let’s make the plot more beautiful by color coding.
medians <- tapply(justices$post_mn, justices$term, median)
plot(x =names(medians),
y= medians,
ylim = c(-.4, 1),
type = "b",
ylab="Conservatism",
xlab="Term",
main="Median of US Supreme Court over Time",
xaxt="n", ## removes the x-axis
las=1)
## Adds text
text(x=names(results), y=(medians - .14), results, cex=.35)
## Adds color-coded points on top of existing points
points(x =names(medians),
y= medians,
## Adds colors according to how results is coded
col= ifelse(results == "AMKennedy", "orange",
ifelse(results =="SDOConnor", "light blue",
ifelse(results == "JGRoberts", "purple",
"red3"))),
pch=15, # point type- squares
cex=1.5) # size of points
## Adds custom x-axis at the specific years included in names(medians)
axis(1, names(medians), cex.axis=.6)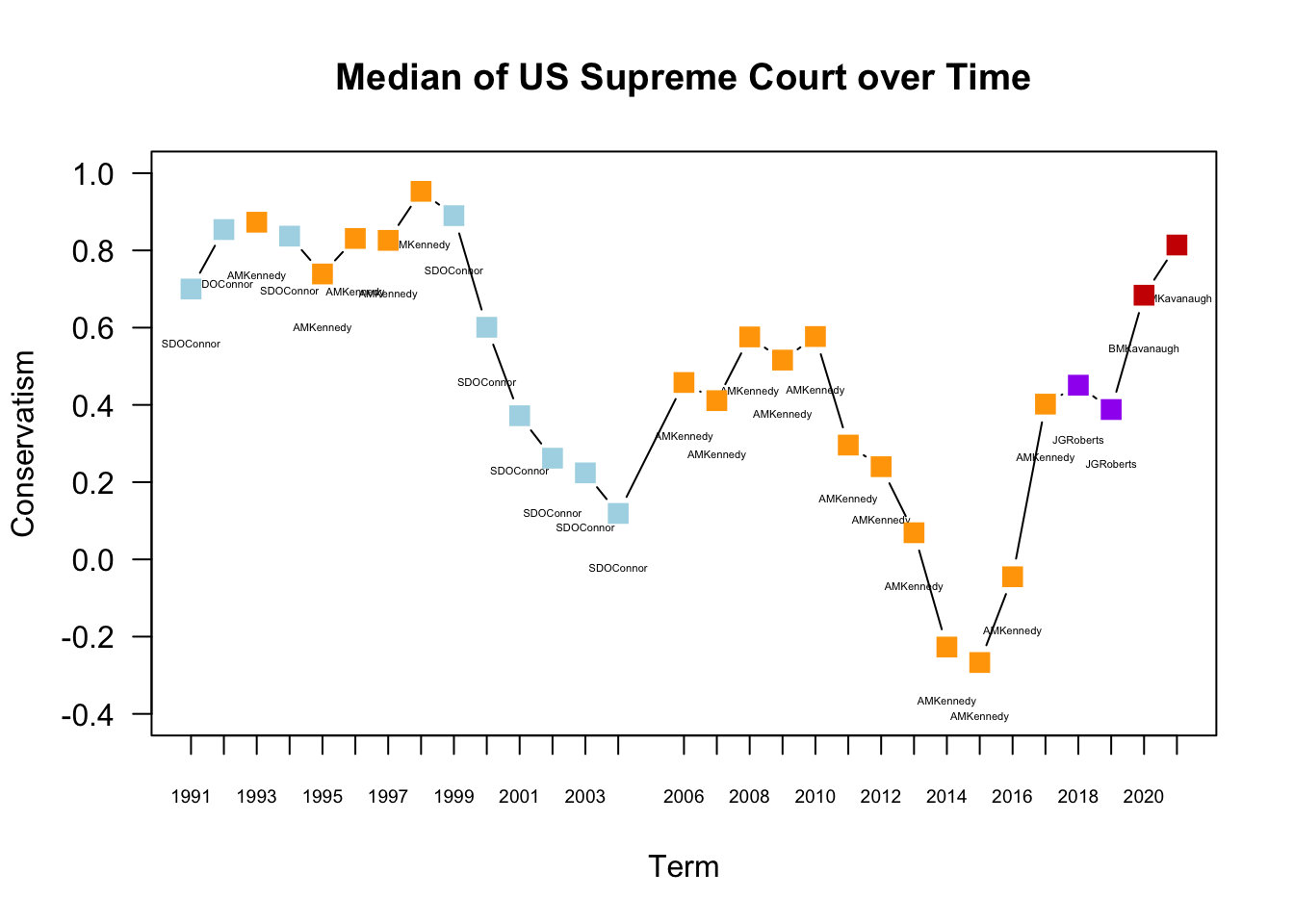
We have used the points() function. This adds an additional layer of points to a plot. It works much like the plot function in that in takes a set of x and y coordinates.
We could change the look of the plot even more by adding a legend and altering the borders and look of the plot.
medians <- tapply(justices$post_mn, justices$term, median)
plot(x =names(medians),
y= medians,
ylim = c(-.4, 1),
type = "b",
ylab="Conservatism",
xlab="Term",
main="Median of US Supreme Court over Time",
xaxt="n", # removes x axis
las=1, # changes the orientation of the axis labels
lwd=2, # increases the thickness of the lines
tick=F, # removes the tick marks from the axis
bty="n") # removes the plot border
## adds horizontal dashed gray lines
abline(h=seq(-.4, 1, .2), lty=2, col="light gray")
## Adds a legend
legend("bottomleft", pch=15, col = c("orange", "light blue", "purple", "red3"),
c("Kennedy", "O'Connor", "Roberts", "Kavanaugh"), bty="n")
## Adds the color-coded points
points(x =names(medians), y= medians,
col= ifelse(results == "AMKennedy", "orange",
ifelse(results =="SDOConnor", "light blue",
ifelse(results == "JGRoberts", "purple",
"red3"))),
pch=15, cex=2)
## Adds our custom x-axis
axis(1, names(medians), cex.axis=.6, tick=F)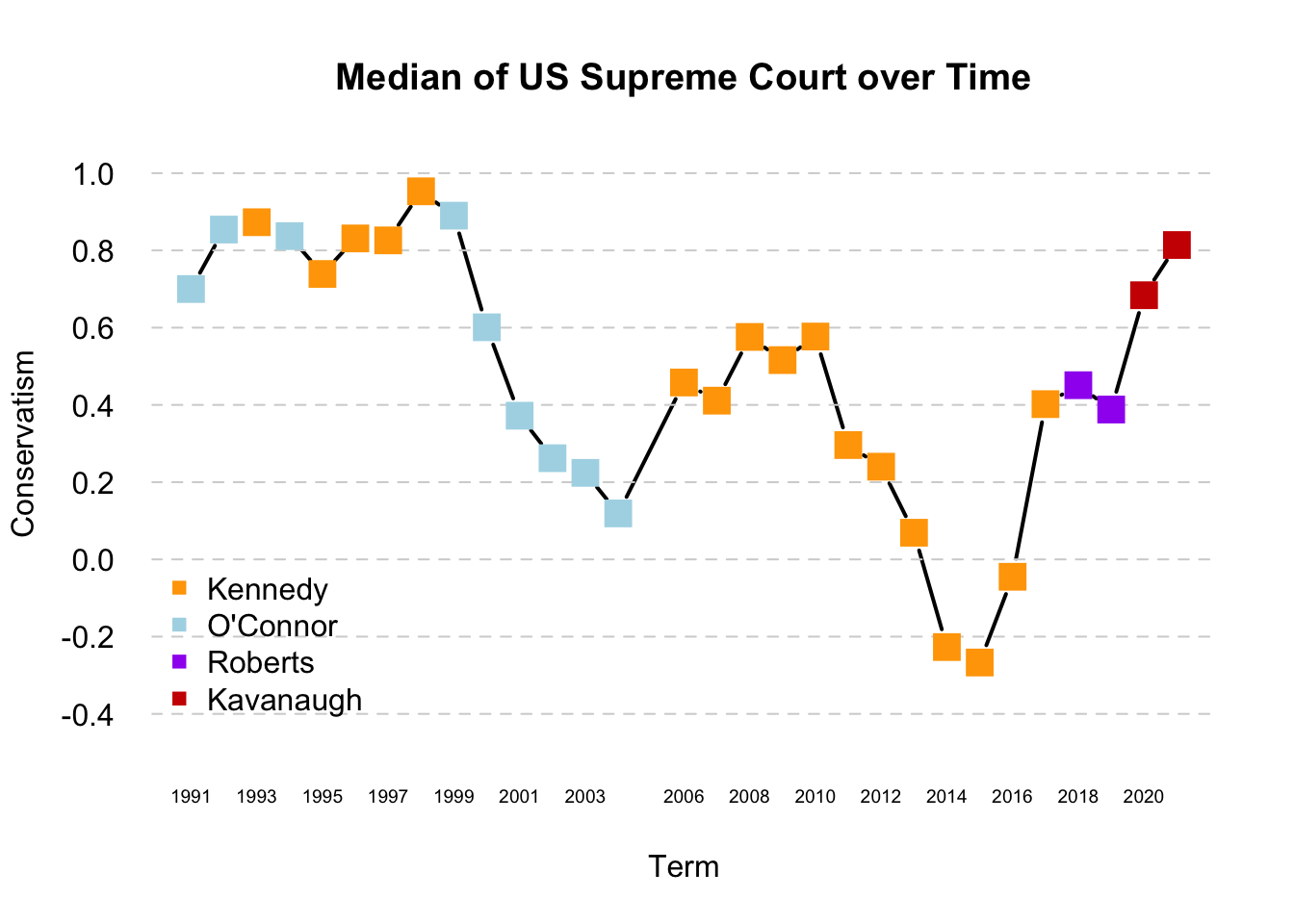
6.2.4 Wrapping Up
We have calculated and visualized how the median U.S. Supreme Court Justice and Justice’s ideology has changed over the past three decades.
- This gave us additional practice with loops and visualization
- We also gained exposure to an example of how political scientists take a large amount of information– votes on all Supreme Court cases– and try to summarize it using a single number that represents how liberal or conservative a justice is
This type of information can be used for many social science goals: 1) To describe trends in the Court 2) To help explain why the Court has voted a particular way on recent cases 3) To predict how the Court will vote in the future as new justices arrive.
With Amy Coney Barrett now on the Court for multiple terms and Ketanji Brown Jackson beginning to decide cases, the MQ scores will continue to be updated to allow for future exploration of these dynamics.