This section will provide an overview of considerations and basic modeling strategies for data that include repeated observations across units or over time. This may relate to panel data, time series cross-sectional data, and hierarchical data.
To motivate why we might use different models in these cases, please watch this video from Ben Lambert (like and/or subscribe to support him).
Donald P. Green, Soo Yeon Kim, and David H. Yoon. “Dirty Pool.” International Organization 55, 2, Spring 2001, 441-468.
Nathaniel Beck and Jonathan Katz. “Throwing Out the Baby with the Bath Water: A comment on Green, Kim, and Yoon.” International Organization 55, 2, Spring, 2001, pp. 487-495.
12.1 Motivating Data Groupiness
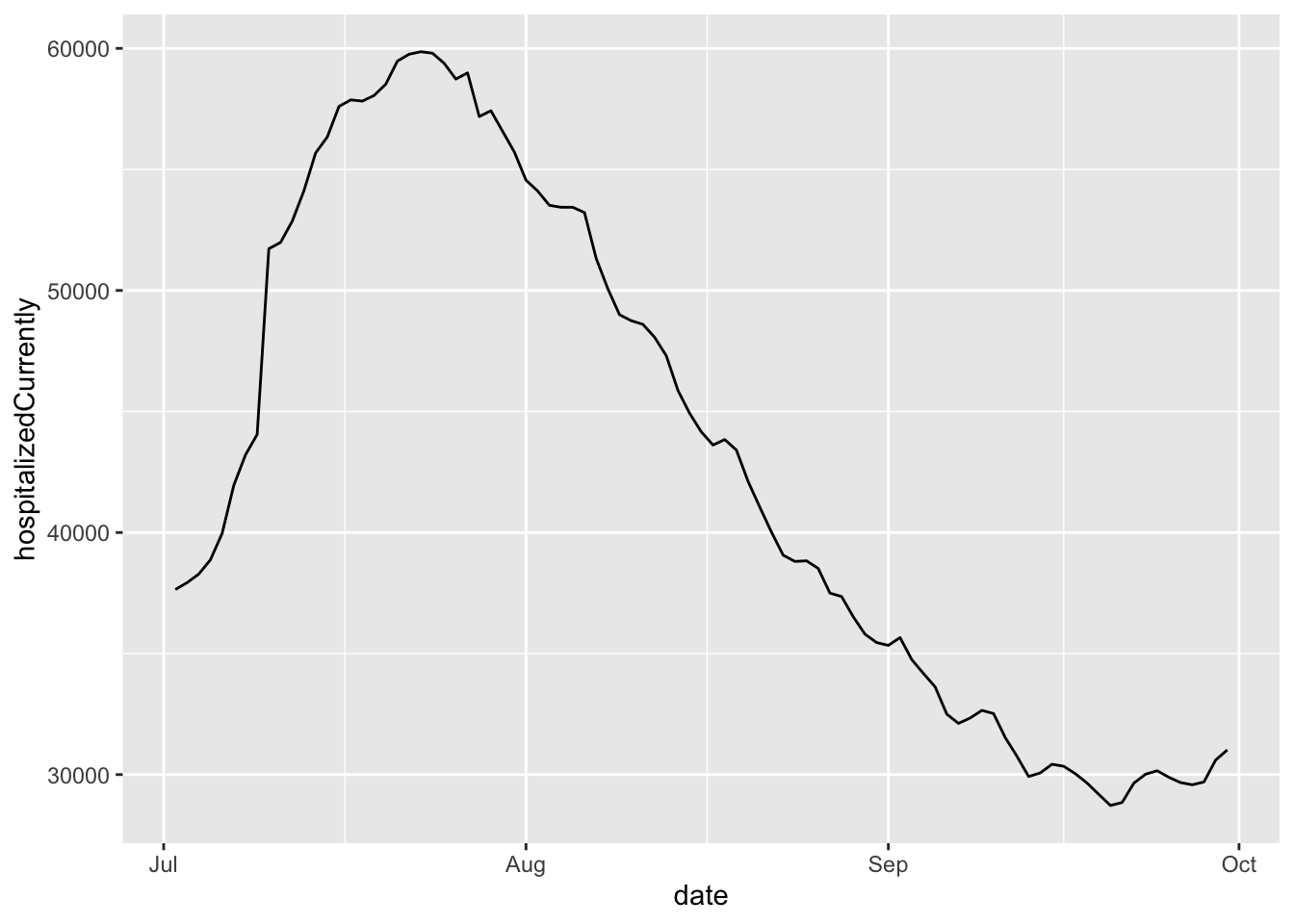
In this section, we are going to use data from the CDC on national and state-level COVID hospitalizations and positive case increases between July 2020- end September 2020.
date hospitalizedCurrently positiveIncrease state
8849 2020-09-30 53 104 AK
8850 2020-09-30 776 1147 AL
8851 2020-09-30 484 942 AR
8853 2020-09-30 560 323 AZ
8854 2020-09-30 3267 3200 CA
8855 2020-09-30 264 511 CO
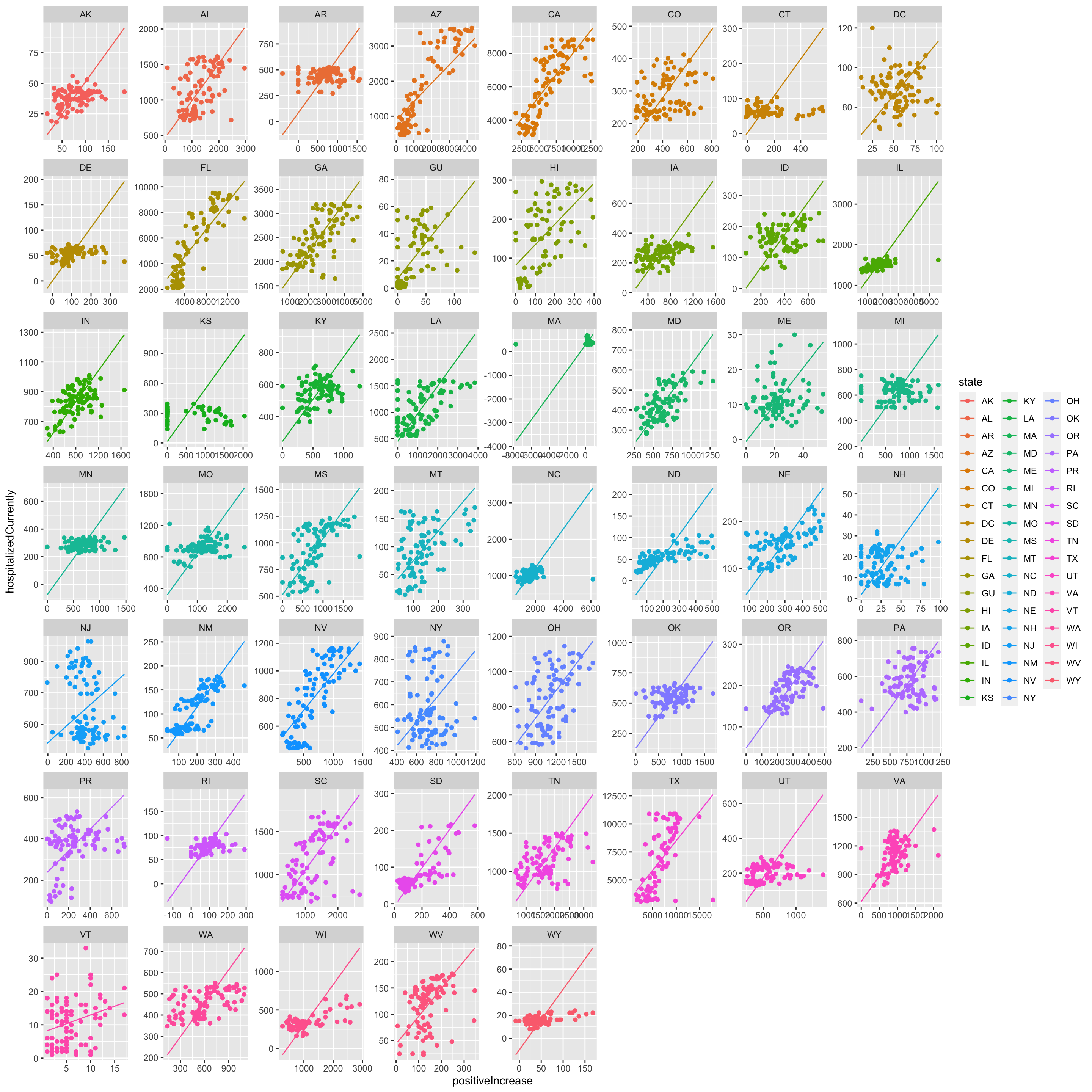
During this time period, the national level of hospitalizations was declining.
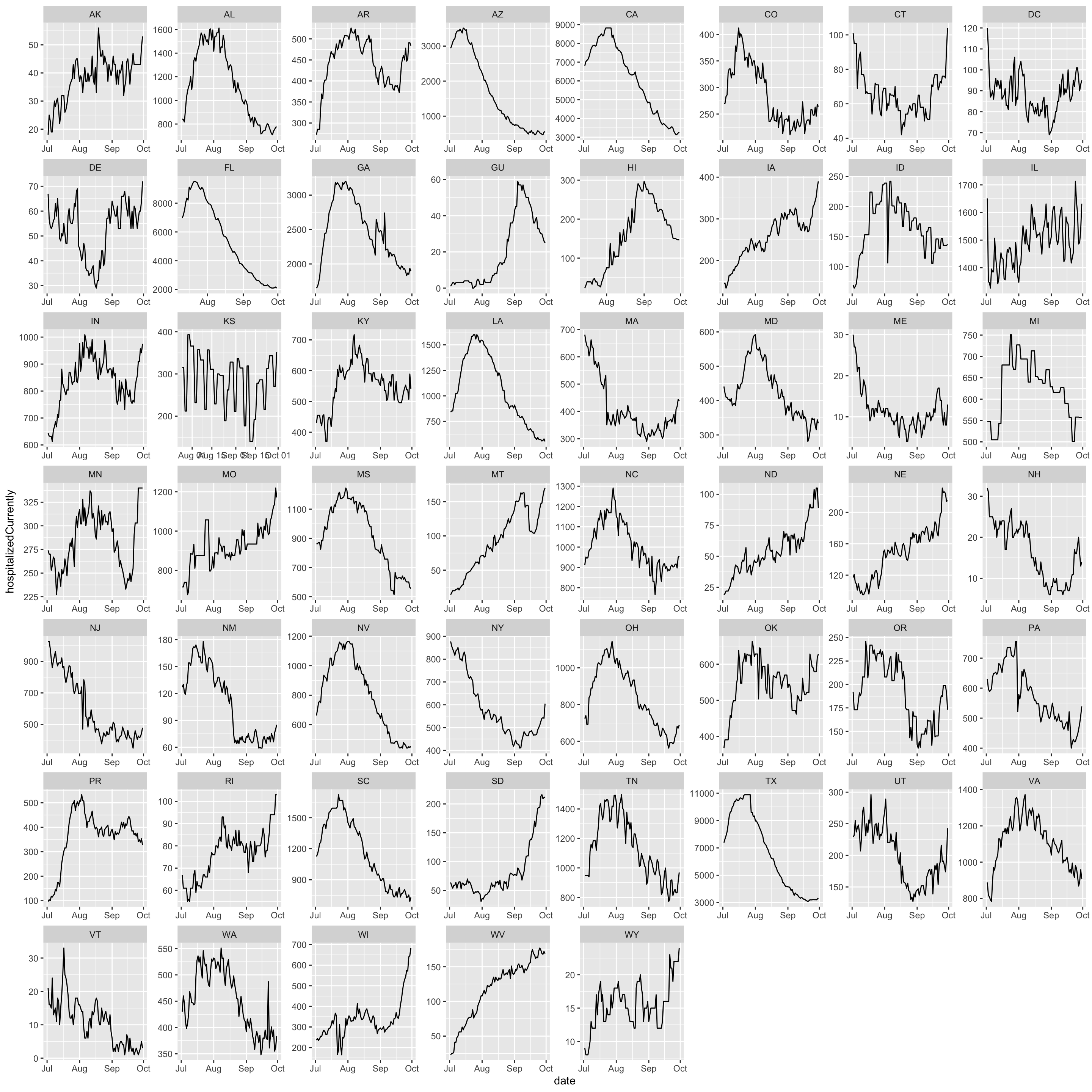
However, the national data represents aggregated state-level data. It is possible that these trends might look different if we looked within each state.
When we have data that are grouped in some way, it is important to consider how group-specific factors may influence the results.
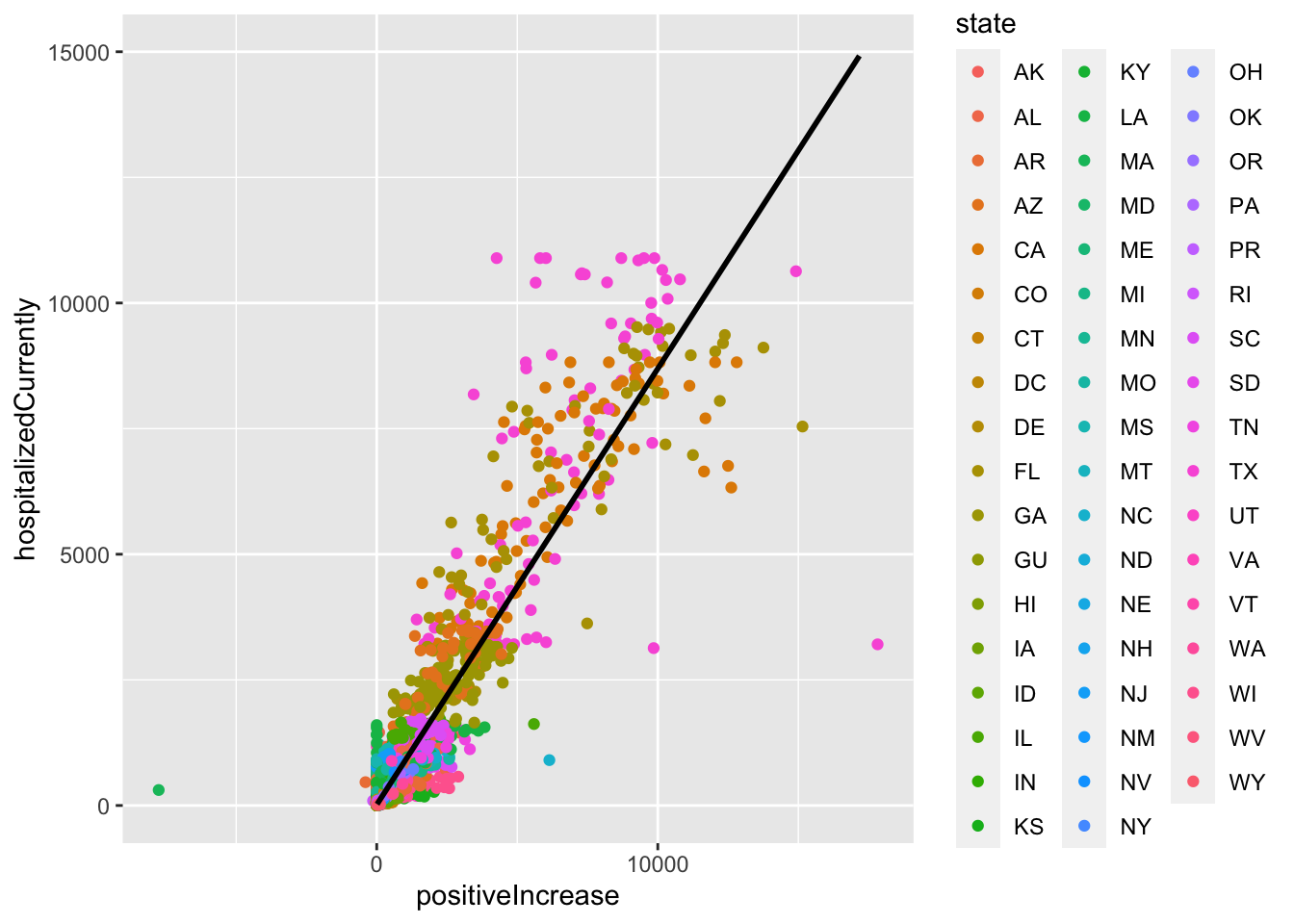
Let’s look at the relationship between positive increases in cases and hospitalizations using the state-level data. Note, we are not epidemiologists here, so this is in no way exactly how you would want to model this in practice. We will leave that to the experts. Nonetheless, it will give us some visualizations. The regression line below is from the following regression, which pools across states and dates:
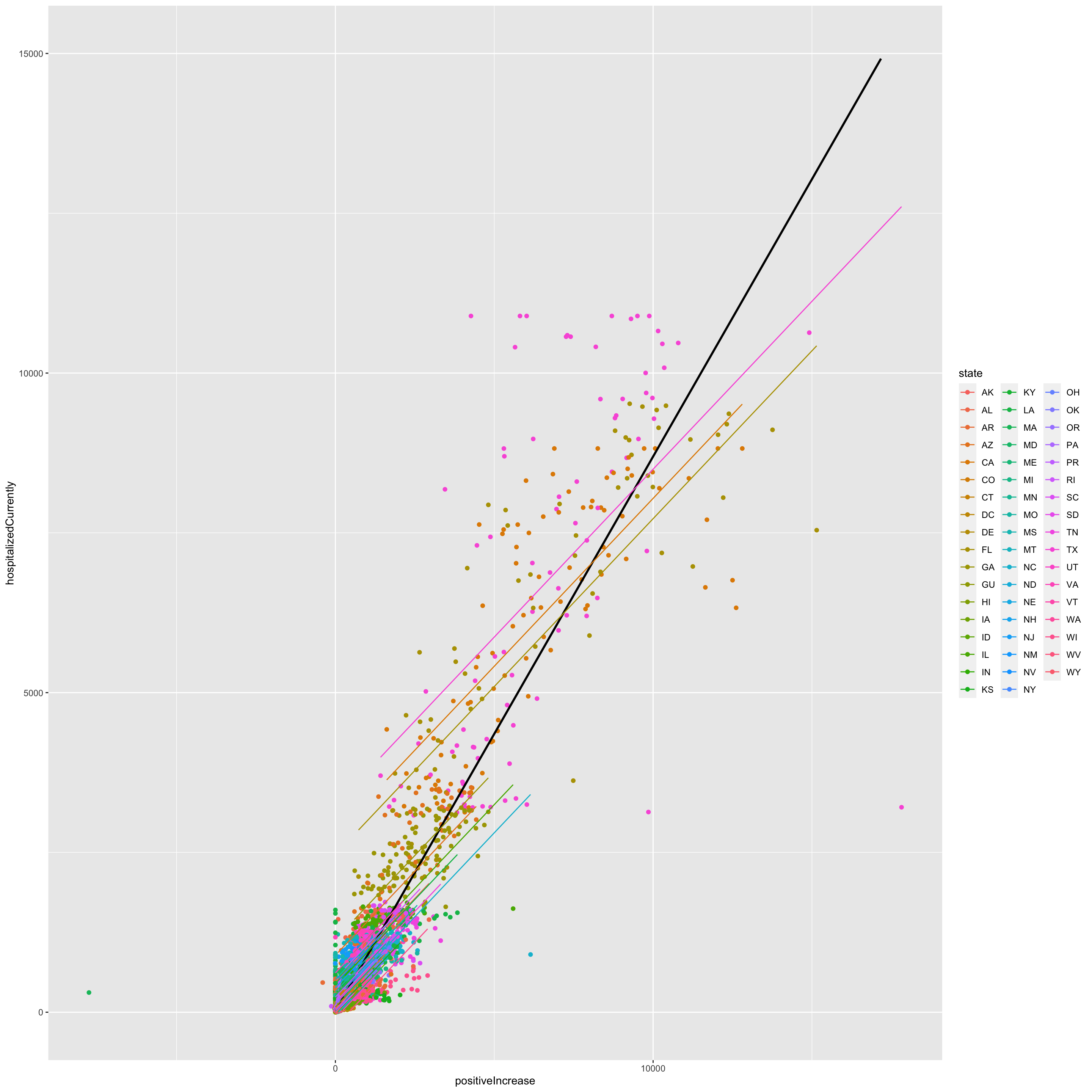
One thing we could do to account for the variation in cases, is to add controls for state. This is called adding “fixed effects.” It allows the intercept for each state to be different in regression, but the slopes are considered the same.
\(Y_i, X_i\) now become \(Y_{it}, X_{it}\) where \(i\) is a unique indicator for the unit and \(t\) is a unique indicator for time (or question, task, etc., other repeated measurement)
For example, perhaps we observe a set of \(N\) European countries, each indexed by \(i\) over \(10=T\) years, each indexed by \(t\).
The dataset can be represented in “wide” or “long/stacked” format (see section 2 of the course notes)
Can get more complicated. Perhaps we have a Member of Parliament in a year in a country: \(Y_{itj}, X_{itj}\). Now we have three indices for our variables.
We also might not have variation over time, but instead, multiple levels of units– perhaps students (\(i\)) nested in schools (\(j\)).
Why do we like this type of data in social science?
We think some \(Z\) variable is related to some \(Y\) outcome.
So we test this with data by comparing data that vary on \(Z\) to see if they vary systematically on \(Y\).
Our goal is to isolate \(Z\). We want to “control” on everything that differs between our units that could affect \(Y\) except for \(Z\), which varies.
Problem: this can feel almost impossible in cross-sectional data
Example: Bob and Suzy probably differ in a million ways, but we can only measure and account for so many covariates
Example: France and Germany probably differ in a million ways, but we can only measure and account for so many covariates
This makes comparing Bob vs. Suzy and France vs. Germany for our variation is a somewhat suspect way to show how \(Z\) relates to \(Y\) if we cannot control on all possible relevant factors.
Possible solution: enter repeated observations
Idea: Bob in wave 1 is probably pretty similar to Bob at wave 2. This might be a more sensible comparison than Bob vs. Suzy.
Idea: France in 1968 vs. France 1970 is probably a more sensible comparison than France vs. Germany
So, perhaps we incorporate Bob vs. Bob and Suzy vs. Suzy; France vs. France and Germany vs. Germany comparisons instead of just making between-unit comparisons.
Issue: need to learn new methods to account for our grouped/repeated data structure.
When we have grouped/longitudinal data, many of these assumptions are likely violated. For elaboration, see the video on the previous page that discusses how unobserved factors related to particular geographical areas might influence the explanatory variable crime rate video.
Let’s take a look at why.
What if we have \[\begin{align*}
Y_{it} = \beta_0 + \beta_1 x_{it} + \epsilon_{it}
\end{align*}\]
We could still treat this as OLS if we believe the assumptions hold. But often, we are concerned that our model actually looks like this:
We think there may be \(c_i\) unobserved characteristics about our units \(i\) that are related to our explanators. If unaccounted for and left as part of the error term, this would cause bias in our coefficients.
Note: in OLS, we assume Cov\((c_i + \epsilon_{it}, x_{it}) = 0\). Here, we believe there may be unmeasured factors that induce covariance between \(c_i\) and \(x_{it}\).
One Solution: fixed effects: removes time-constant unobserved characteristics about our units.
12.3 Fixed Effects
In fixed effects, we allow the intercept to be different across our \(N\) groups (e.g., countries), where these terms are going to account for time-invariant (time constant) characteristics of these areas.
where \(\alpha_{i}\) absorbs all unobserved time-invariant characteristics for unit \(i\) (e.g., features of geography, culture, etc.)
This is huge! It’s going to help us get around the assumption we just talked about. The idea is that when we are comparing observations within a particular unit (e.g., within France), all of those time-invariant characteristics specific to France are held constant.
Below we discuss how to estimate fixed effects models. It is not the solution to everything. Keep these in mind.
Still assume homoskedastic errors \(\rightarrow\) may want to adjust the SE’s.
Cannot model “level-2” factors. Problematic if that’s what you’re interested in! (E.g., if you have time-invariant country-level covariates). Can only do this through interactions.
For example, suppose we have a measure of a country’s culture (\(culture_{i}\)), that does not vary over time. We could not include that in our regression model because the model removes all time-invariant characteristics. In contrast, if something like country GDP changes a lot over time (\(GDP_{it}\)), it could still and should be accounted for.
Only works if you have a decent number of observations
Leverages within-group variation on your outcomes. Need to have this variation for it to make sense!
There are two general approaches for fitting fixed effects estimators: the within-estimator and LSDV.
12.3.1 Within-Estimator
Time Demeaning. First calculate averages of the \(it\) terms.
Note, the mean of \(\alpha_i\) is just \(\alpha_i\) because it does not vary over time. \(\alpha_i\) because: \(\frac{1}{T} \sum_{t=1}^T \alpha_i = \frac{1}{T}*T*\alpha_i = \alpha_i\).
Subtracting we get: \[\begin{align*}
Y_{it} - \bar y_i &= (\alpha_i -\alpha_i) + \beta(x_{it}- \bar x_i) + (\epsilon_{it}- \bar \epsilon_i)\\
\widetilde{Y_{it}} &= \beta\widetilde{x_{it}} + \widetilde{\epsilon_{it}}
\end{align*}\]\(\beta\) is estimated just from deviations of the units from their means. Removes anything that is time-constant.
This video from Ben Lambert goes through the demeaning process.
12.3.2 Least Squares Dummy Variable Regression
We can estimate the equivalent model by including dummy variables in our regression. This is sometimes why you have seen authors add dummies for region and call them “fixed effects.”
OLS with dummy variables for each unit (e.g., countries). Start with “stacked” data where: \(Y = X\beta + U\delta + \epsilon\).
\(Y\) is \(NT \times 1\) outcome vector where \(N\) is number of \(i\) units and \(T\) is number of time points \(t\).
\(X\) is \(NT \times k\) matrix where \(k\) is the number of covariates plus general intercept
\(U\) is a set of \(m\) dummy variables (e.g., country dummies), leaving one as reference
By accounting for these groups in our regression, we are now estimating how the covariates in \(\mathbf x\) affect our outcomes, holding constant the group– leveraging within-group variation.
12.3.3 Fixed Effects Implementation in R
The plm package allows us to indicate that our data are panel in nature and fit the within-estimator.
Run install.packages("plm") and load Grunfeld. 200 observations at the firm-year level. Here, we can think of firms as indexed by \(i\) and years indexed by \(t\).
These data are used to study the effects of capital (stock of plant and equipment) on gross investment inv.
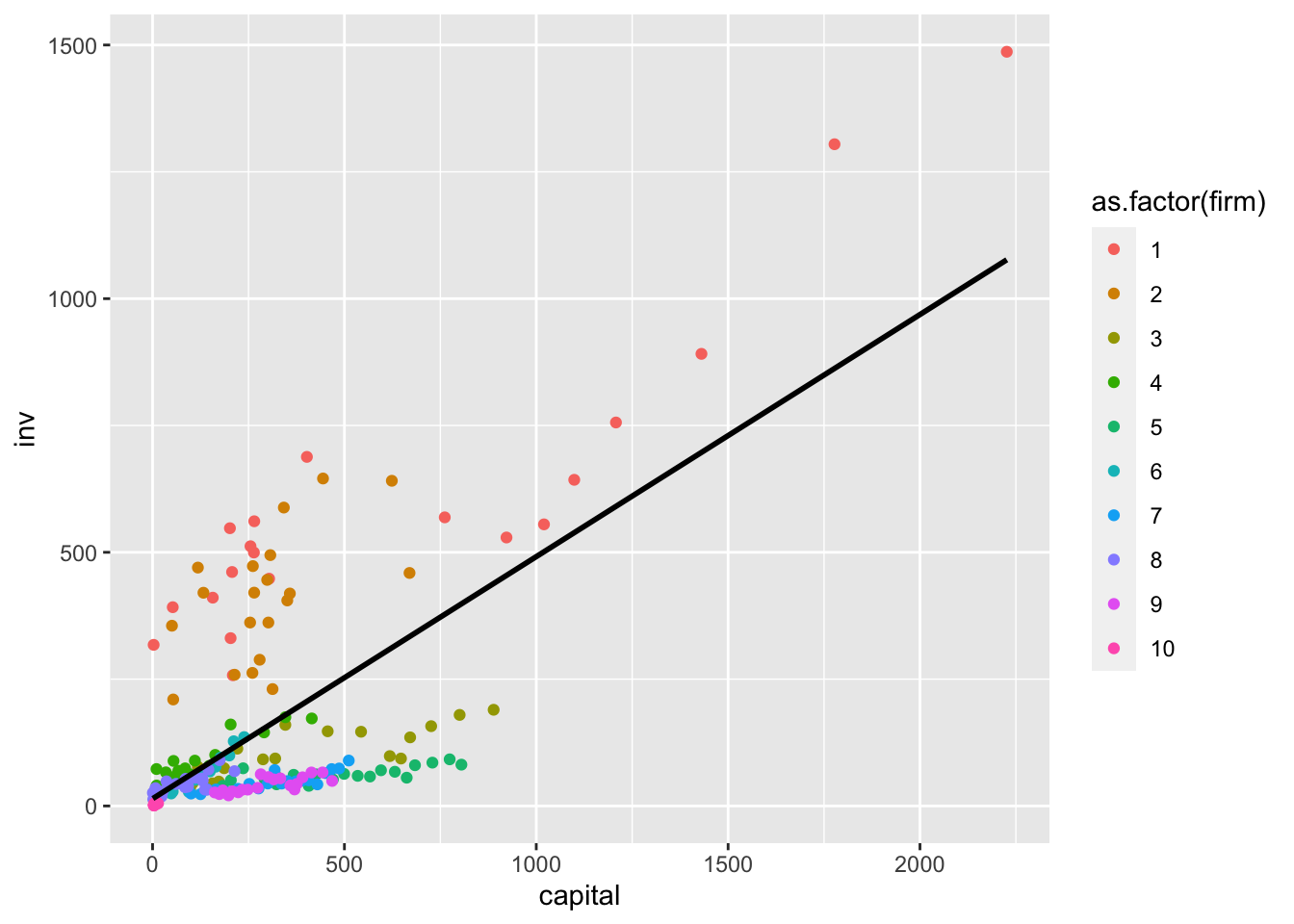
Let’s first run a standard OLS model, which we will call the “pooled” model because it pools observations across firms and years without explicitly accounting for them in the model. We can use the standard lm model to do this or the plm function from the plm package by indicating model="pooling". Both give equivalent results.
## Pooled modelfit.pool <-plm(inv~ capital, data = Grunfeld, model ="pooling")coef(fit.pool)["capital"]
capital
0.4772241
## Equivalentfit.ols <-lm(inv~ capital, data = Grunfeld)coef(fit.ols)["capital"]
capital
0.4772241
We could visualize this model as follows by plotting the regression line. This provides a good benchmark against which we can see how fixed effects change the results. Note that the line ignores which firm that the data are coming from, using between-firm variation to help fit the regression slope.
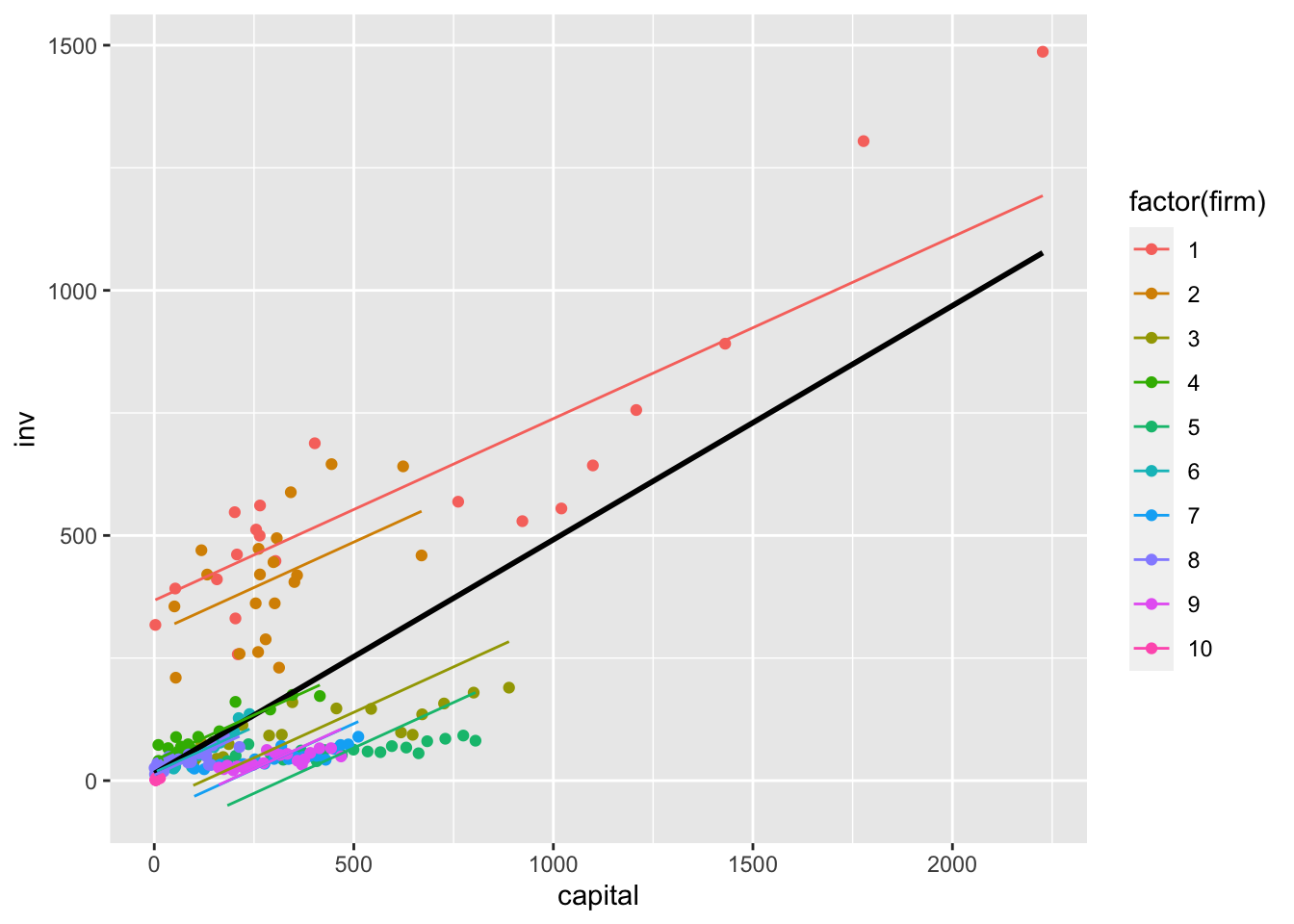
Let’s now fit our fixed effects model. Here, we have to add an argument that specifies which variables are indexed by \(i\) and \(t\) so that plm knows how to incorporate the individual firm units. We will first fit the within model using the plm package. We can then use lm by explicitly adding dummy variables. You will note that the individual dummy variable coefficients are only included in the output of lm and not plm. When you have a large number of units, it might be more computationally efficient and cleaner to use plm. However, both give us equivalent results for our coefficients of interest.
## Within model with firm fixed effectsfit.within <-plm(inv~capital, data = Grunfeld, model ="within", index =c("firm", "year"))coef(fit.within)["capital"]
capital
0.3707496
## numerical equivalentfit.lsdv <-lm(inv~ capital +as.factor(firm), data = Grunfeld)coef(fit.lsdv)["capital"]
capital
0.3707496
Recall, what fixed effects does is create a different intercept by firm. We can visualize this by generating predicted gross investments for each observation in our data.
Fixed effects leverages within-firm variation to fit the regression model. That is, holding constant the firm, how does capital influence investment, on average?
Here, we see that when the variation is coming from within-firm, the estimated slope for the capital variable is slightly more shallow than when the pooled model used data across different firms to estimate the slope. Sometimes, the difference between the pooled OLS and fixed effects estimation can be so severe as to reverse the sign of the slopes. This is the idea of Simpson’s paradox discussed here.
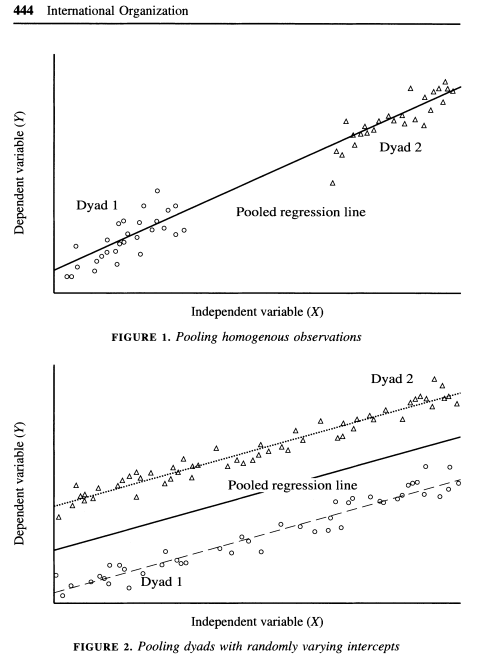
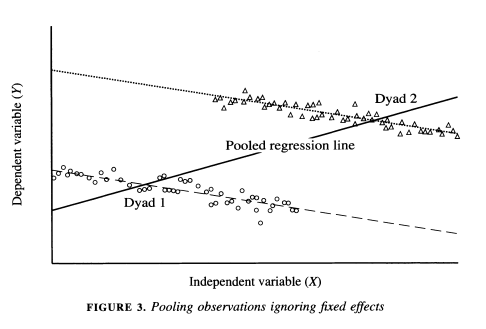
Green et al. (2003) also discuss the dangers of pooling data in certain cases in the article ``Dirty Pool.” Below are three examples. In the first two, pooling vs. fixed effects will not make much of a difference, but it will in the third.
As the authors describe, “The plot in Figure 1 depicts a positive relationship between X and Y where N = 2 and T = 50. Because both dyads share a common intercept, pooling creates no estimation problems. One obtains similar regression estimates regardless of whether one controls for fixed effects by introducing a dummy variable for each dyad. A pooled regression is preferable in this instance because it saves a degree of freedom. In Figure 2 we encounter another instance in which dyads have different intercepts, but there is no correlation between the intercepts and X. The average value of the independent variable is the same in each dyad. Again, pooled regression and regression with fixed effects give estimates with the same expected value. Figure 3 illustrates a situation in which pooled regression goes awry. Here, the causal relationship between X and Y is negative; in each dyad higher values of X coincide with lower values of Y. Yet when the dyads are pooled together, we obtain a spurious positive relationship. Because the dyad with higher values of X also has a higher intercept, ignoring fixed effects biases the regression line in the positive direction. Controlling for fixed effects, we correctly ascertain the true negative relationship between X and Y” (443-445).
12.3.4 Standard errors with fixed effects
Even if we use fixed effects, we may want to adjust standard errors. Fixed effects assumes homoskedasticity (constant error variance). We might instead think that the random error disturbances are correlated in some way or vary across time or units. For example, we might fear we have serial correlation (autocorrelation), where errors are correlated over time. Below are a few options.
Clustered standard errors. We came across this before in our section on ordinal probit models and the Paluck and Green paper. This blog post discusses why you may still want to cluster standard errors even if you have added fixed effects.
Note: the functions below are designed to work with the plm package and models. For models fit through other functions, you may need to use different functions to make adjustments. See section 8.5.1. For linear models lm_robust from the estimatr package works well. For other models, see the alternative applications in that section.
## Cluster robust standard errors to match stata (c only matters if G is small). Can omit if do not want to adjust for degrees of freedom.## Generally want G to be 30 or 40G <-length(unique(Grunfeld$firm))c <- G/(G -1)sqrt(diag(c*vcovHC(fit.within,type ="HC1", cluster ="group")))
capital
0.06510863
Panel corrected SE: Beck and Katz have also developed standard errors for panel data. Explained in the documentation, observations may be clustered either by “group” to account for timewise heteroskedasticity and serial correlation or by “time” to account for cross-sectional heteroskedasticity and correlation. This is sensitive to \(N\) and \(T\).
## Alternative: Beck and Katz panel corrected standard errorssqrt(diag(vcovBK(fit.within, cluster ="group"))) # also can change type
capital
0.04260805
Alternative: Adjusted for heteroskedasticity and/or serial correlation.
sqrt(diag(vcovHC(fit.within, type ="HC1", method ="arellano")))
You should use caution when adding fixed effects to binary models, such as the logit. They can suffer from the “incidental parameters” problem. Instead of using the logit, with a large number of fixed effects (some would even say not that large), you can use a linear probability model or the conditional logit mode.
For a resource on fitting the conditional logit in R, see here.
The xtlogit fe command in Stata fits this type of model
Note that computing marginal effects and predictions from this model can be more difficult
12.4.2 Two-way fixed effects
We might be concerned not just about unobserved unit effects but also unobserved time effects \[\begin{align*}
Y_{it} = \beta_0 + \beta_1x_{it}+ (c_i + v_t + \epsilon_{it}).
\end{align*}\]
Here, we may include fixed effects for both units and time. Warning: can be difficult to interpret.
Alternative, sometimes instead of including dummies for each \(t\) period, people will include a “time trend.” This could be a linear time trend, for example, a year variable treated as numeric.
The within- and LSDV estimators are not the only way to incorporate fixed effects into our models. Another type of estimation is first differences.
\(\Delta Y_{it} = \beta \Delta x_{it} + \Delta \epsilon_{it}\) where, for example, \(\Delta Y_{it} = Y_{it} - Y_{it- 1}\). Instead of demeaning over all time. We subtract the previous instance.
Both remove unobserved heterogeneity (i.e., \(\alpha_i - \alpha_i\))
Requires variation in time. \(t\) vs. \(t-1\) or else \(x_{it} - x_{it-1} = 0\) and falls out
When \(T = 2\), fixed effects = first differences
When \(T > 2\), fixed effects \(\neq\) first differences
Under assumptions, both unbiased and consistent
When no serial correlation, then \(SE(\hat \beta_{FD}) > SE(\hat \beta_{FE})\)
If \(\Delta \epsilon_{it}\) are uncorrelated, FD preferred.
In general, hopefully both produce very similar results
I recommend watching this video by Ben Lambert who provides a summary overview of the differences between fixed effects, first differences, and pooled OLS.
12.4.4 Additional Models in R
## first differencesfit.fd <-plm(inv~value+capital, data = Grunfeld, model ="fd", index =c("firm", "year"),effect ="individual")coef(fit.fd)["capital"]
capital
0.2917667
## firm and year effectsfit.twoway <-plm(inv~value+capital, data = Grunfeld, model ="within",index =c("firm", "year"),effect ="twoways")coef(fit.twoway)["capital"]
capital
0.3579163
12.5 Random Effects
We have now discussed pooled OLS and fixed effects estimation (often called no-pooling). We will now shift to estimation strategies that involve partial-pooling.
Tradeoff between complete pooling and no-pooling (i.e., fixed effects).
Complete pooling ignores variation between groups BUT
No-pooling may overfit the data within group and prevents estimation of “level-2” effects.
To motivate partial-pooling, we can take a look at an example.
Example: What will Mookie Betts’s batting average be in 2018?
In March 2018, Mookie went 2 for 11. If we fit his average just based on his data \(n_{mookie}=11\), we get an average of .182.
Over the entire season, Mookie ended up with an average of .346. Is there any way we could have adjusted our initial estimate to end up with a more accurate estimate of what his average would be?
Possible solution: fit the average based on a combination of Mookie’s data (\(\bar y_{mookie}\)) and data from all players (\(\bar y_{all}\)). It will move Mookie’s estimate closer to the “grand” average across all players by partially pooling his data with the others.
12.5.1 Random effects models
In random effects estimation, for the \(ith\) observation, we allow the intercept \(\alpha\) to vary by some unit \(j\). Where \(j[i]\) refers to the group-level coding for the \(ith\) observation. Perhaps \(j=3\) for \(j[4]\), the 4th observation.
Assume we have a random sample of \(n\) units within each \(j\), \(n_j\)
Then, our estimate for a given group \(j\) is a weighted average of observations within \(j\) (\(\bar y_j\)) and the mean overall \(j\)’s (\(\bar y_{all}\)).
These are weighted according to the variance in \(y\) within \(j\) (\(\sigma^2_y\)) and variance among the averages of \(y\) across \(j\) (\(\sigma^2_\alpha\))
This video by Ben Lambert shows how this idea of a “weighted average” extends to regression with covariates. Random effects provides a balance between fixed effects and OLS, no-pooling and pooling, which is why it is considered partial pooling.
When \(\sigma^2_\alpha\) is very small, random effects will be close to OLS.
If \(\sigma^2_\alpha\) is very big, then the weighted balance will be closer to fixed effects.
Differences with pooling and no pooling
Pooling- intercepts all fixed to \(\alpha\) (\(\sigma^2_{\alpha} = 0\))
No pooling- \(\alpha_j\)’s correspond to models fit within each \(j\). Do not come from a common distribution.
A downside: cannot include time-invariant group characteristics.
Partial pooling (shrinkage)- \(\alpha_j\)’s have a probabilitiy distribution \(\alpha_j \sim N(u_{\alpha}, \sigma^2_{\alpha})\). Has the effect of pulling estimates of \(\alpha_j\) toward the mean of all groups.
\(\alpha_j = u_{\alpha} + \eta_j\) where \(\eta_j\) is a group-level error term (model without group-level predictors)
Must assume\(\mathbf E(x_{ij}\alpha_{j[i]}) = 0\). Unmodeled, unmeasured characteristics about your group-level effects (e.g., countries) that affect the outcome are not correlated with the regressors in your model.
Good news: Can include group-level predictors: Now \(\alpha_j\) coeffcients have a distribution \(\alpha_j \sim N(U_j\gamma, \sigma^2_\alpha)\)
Scholars can have strong feelings about these choices, which often vary by subfield conventions along with the specifics of any research question. For example, the Green et al. piece advocating the use of fixed effects called pooling a ``Dirty Pool.” In response, Beck and Katz made the analogy that “Green, Kim, and Yoon’s fixed-effects”cure” for column 3 is akin to curing a cold with chemotherapy” (492).
12.5.2 Random Effects Implementation in R
If comparing with fixed effects, can useplm.
## Firm random effectsdata("Grunfeld")fit.re <-plm(inv~value+capital, data = Grunfeld, model ="random", index =c("firm"), effect ="individual")coef(fit.re)["capital"]
capital
0.308113
One approach to deciding whether to use fixed vs. random effects is the Hausman test, which assesses the correlation assumption.
## Compares beta hats for FE and RE and covariance## Under null hypothesis of no correlation estimates should be similar## Under null, RE preferred due to efficiency gainsfit.within <-plm(inv~capital+value, data = Grunfeld, model ="within", index =c("firm", "year"))phtest(fit.within, fit.re)
Hausman Test
data: inv ~ capital + value
chisq = 2.3304, df = 2, p-value = 0.3119
alternative hypothesis: one model is inconsistent
With a small p-value, we reject the null, suggesting fixed effects is preferred for this model. With a large p-value, we fail to reject the null, suggesting random effects is preferred. Note: while the test provides one way to adjudicate between fixed and random effects, it cannot tell you if the model you have specified is “correct.”
12.5.3 Using lme4 for random effects
More flexible package for random effects: lme4. Uses “REML” by default- a variation on MLE. Ben Bolker provides a great overview of the package here. Here is a video walking through the syntax and output.
library(lme4)fit.re2 <-lmer(inv~ value + capital + (1| firm), data = Grunfeld)## extract model coefficientsfixef(fit.re2)["capital"]
capital
0.3081881
WHERE ARE MY P VALUES?!?!?!?!
summary(fit.re2)$coefficients
Estimate Std. Error t value
(Intercept) -57.8644245 29.37775852 -1.969668
value 0.1097897 0.01052676 10.429581
capital 0.3081881 0.01717127 17.947893
Not without controversy. Several ways to compute p-values in these models. This post describes three and provides the code.
For example, if you load the package lmerTest prior to running the model, it will include these results using the Satterthwaite method by default. Clicking on the pdf through this link will give you information on what this package does.
library(lme4)library(lmerTest)fit.re2 <-lmer(inv~ value + capital + (1| firm), data = Grunfeld)summary(fit.re2)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: inv ~ value + capital + (1 | firm)
Data: Grunfeld
REML criterion at convergence: 2195.9
Scaled residuals:
Min 1Q Median 3Q Max
-3.4319 -0.3498 0.0210 0.3592 4.8145
Random effects:
Groups Name Variance Std.Dev.
firm (Intercept) 7367 85.83
Residual 2781 52.74
Number of obs: 200, groups: firm, 10
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) -57.86442 29.37776 11.10912 -1.97 0.0743 .
value 0.10979 0.01053 120.76227 10.43 <2e-16 ***
capital 0.30819 0.01717 193.71234 17.95 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr) value
value -0.328
capital -0.019 -0.368
fit warnings:
Some predictor variables are on very different scales: consider rescaling
Can use output to interpret the nature of the variance. Note that the summary output includes a table for the Random Effects, the variance, and Std. Dev. of each. We can interpret the intercept row as the variability of the intercept across firms (firm-to-firm) variability. The residual is the left-over or within-firm variability. One use of this is to compute the intraclass correlation coefficient (ICC).
The ICC is the proportion of the variance explained by the grouping structure in the population. The Adjusted ICC indexes how strongly measurements in the same group resemble each other. This index goes from 0, if the grouping conveys no information, to 1, if all observations in a group are identical (Gelman & Hill, 2007, p. 258). If the value were really small, you might not need to include random effects for the grouping factor.
Can have multiple levels. E.g., students (\(i\)) nested in classrooms (\(j\)) nested in schools (\(s\)). Each level may or may not have group-level predictors. Example:
Levels can be nested or non-nested. Students are nested in schools, but for a different example, survey questions may not be nested in a single poll. Perhaps some items are repeated across different polls.
Can allow slopes (regression coefficients to vary). Perhaps the effect of gender on student success varies by classroom. Then \(\beta_{2}\) becomes \(\beta_{j, 2} = \gamma_{1s} + r_{1js}\).
Let’s return to the Grunfeld data and fit the following model:
## firm and year random interceptsfit.retwoways <-lmer(inv~ value + capital + (1| firm) + (1| year), data = Grunfeld)fixef(fit.retwoways)["capital"]
capital
0.3106319
Sleep deprivation study: how is a subject’s reaction time associated with sleep deprivation?
data(sleepstudy)## Random intercepts for subjectsfit.re3 <-lmer(Reaction ~ Days + (1| Subject), data = sleepstudy)fixef(fit.re3)["Days"]
Days
10.46729
## Random intercepts for subject, varying slope for daysfit.re4 <-lmer(Reaction ~ Days + (Days | Subject), data = sleepstudy)fixef(fit.re4)["Days"]
Days
10.46729
Recall, the big assumption when adding random effects is that the unobserved group-level random disturbances caught through the intercept terms are not correlated with the regressors.
One suggestion is if concerned about correlation between predictors \(x_i\) and group effects \(\alpha_j\), add group means of regressors as predictors in the model.
## Note the relationship between the three for the first [1] subjectfixef(fit.re3)[1] +ranef(fit.re3)$Subject[1,]
(Intercept)
292.1888
coef(fit.re3)$Subject[1,1]
[1] 292.1888
12.5.6 Generating predicted values for each unit
## Manualallsubjects <-unique(sleepstudy$Subject)for(i in1:nrow(sleepstudy)){ n <-as.character(sleepstudy$Subject[i]) sleepstudy$subjectRE[i] <-ranef(fit.re3)$Subject[n, 1]}## XB like usual, but need to add random effectsyhat <-model.matrix(fit.re3)%*%fixef(fit.re3) + sleepstudy$subjectRE## Compare to Automaticcbind(yhat, fitted(fit.re3), predict(fit.re3, type ="response"))[1:5,]
In this section, we are going to again use data from the CDC on national and state-level COVID hospitalizations and positive case increases between July 2020- end September 2020 to give some examples of how to visualize random effects.
date hospitalizedCurrently positiveIncrease state
8849 2020-09-30 53 104 AK
8850 2020-09-30 776 1147 AL
8851 2020-09-30 484 942 AR
8853 2020-09-30 560 323 AZ
8854 2020-09-30 3267 3200 CA
8855 2020-09-30 264 511 CO
Let’s fit a random effects model with random intercepts for states.
## Random Effectslibrary(lme4)library(lmerTest)fit.re <-lmer(hospitalizedCurrently ~ positiveIncrease + (1| state), data=states)summary(fit.re)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: hospitalizedCurrently ~ positiveIncrease + (1 | state)
Data: states
REML criterion at convergence: 72042.8
Scaled residuals:
Min 1Q Median 3Q Max
-21.4649 -0.1578 0.0012 0.1414 12.3407
Random effects:
Groups Name Variance Std.Dev.
state (Intercept) 439843 663.2
Residual 194044 440.5
Number of obs: 4780, groups: state, 53
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 3.273e+02 9.160e+01 5.131e+01 3.573 0.000779 ***
positiveIncrease 5.317e-01 7.745e-03 4.774e+03 68.644 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
positvIncrs -0.078
fit warnings:
Some predictor variables are on very different scales: consider rescaling
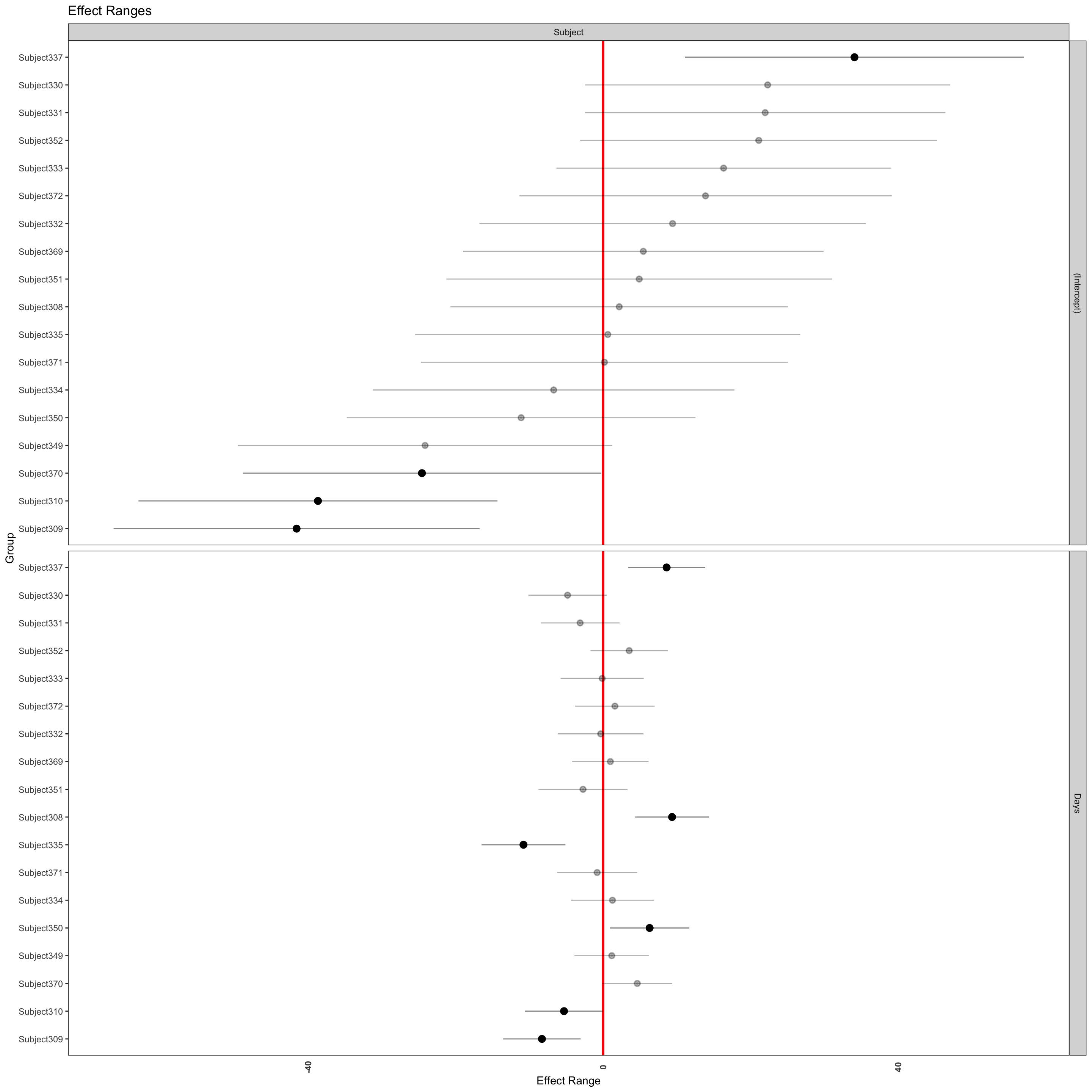
The merTools package also has many useful functions. For example, the plotREsim function acts similar to the dotplot function and will plot the random effects for each group.
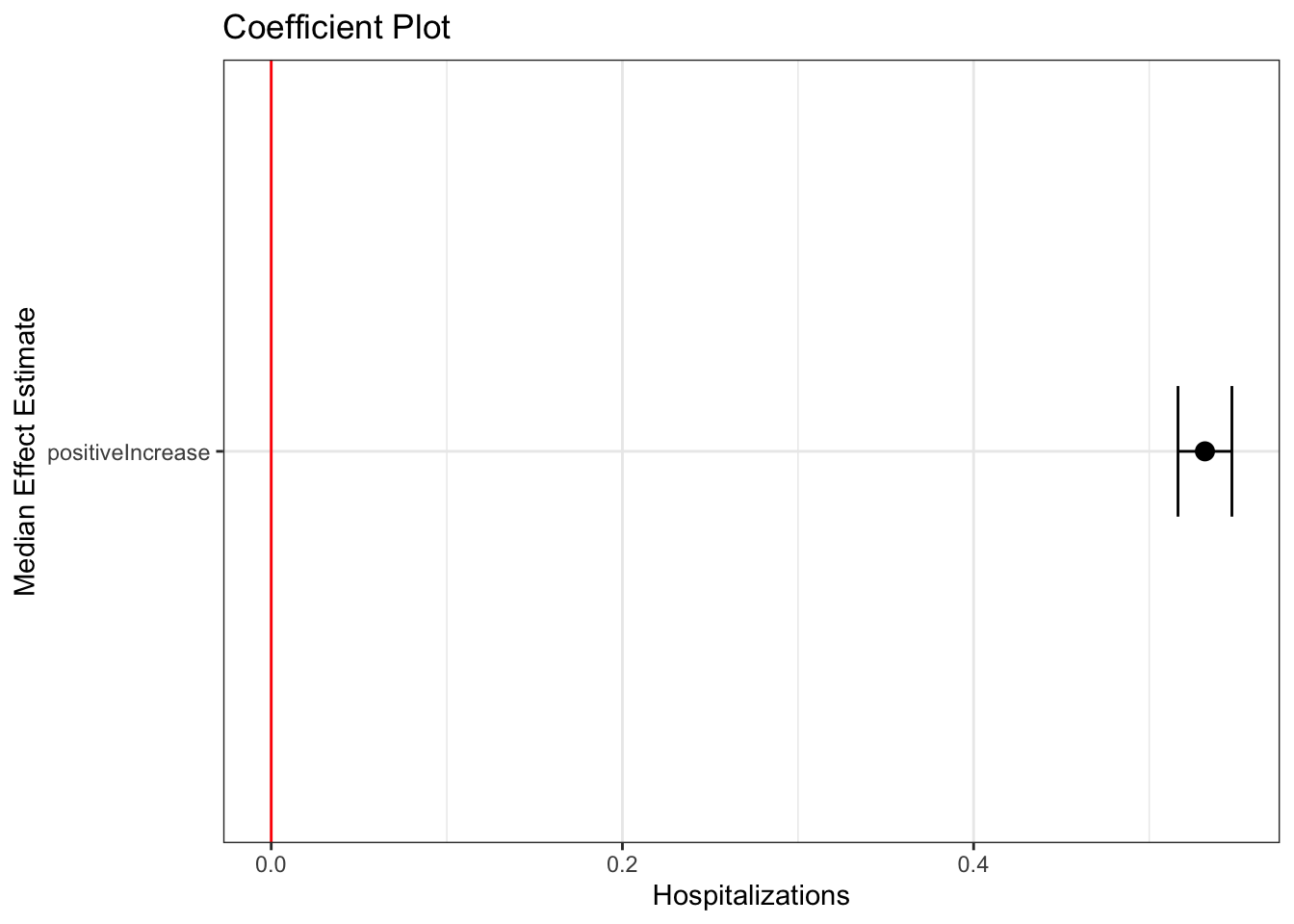
The package also has a tool for plotting the coefficient results with confidence intervals constructed through simulation. If you had several variables, the plot would display all coefficients.
feEx <-FEsim(fit.re, 1000)head(feEx)
term mean median sd
1 (Intercept) 320.9172921 323.2872460 92.223569908
2 positiveIncrease 0.5319686 0.5317333 0.007830214
plotFEsim(feEx) +theme_bw() +labs(title ="Coefficient Plot",x ="Median Effect Estimate", y ="Hospitalizations")
For more on this tool’s capabilities, particularly as it relates to generating predicted values, see here.
Finally, let’s try another model using the sleepstudy data to show how the plots can also incorporate varying slopes.
library(lme4)data("sleepstudy")## Random intercepts for subject, varying slope for daysfit.re4 <-lmer(Reaction ~ Days + (Days | Subject), data = sleepstudy)
Generalized Linear Mixed Effects Regression: glmer() is to lmer() as glm() is to lm(). Example:
## What if reaction time was dichotomous? sleepstudy$rdi <-ifelse(sleepstudy$Reaction >mean(sleepstudy$Reaction), 1, 0)## GLMER with logitfit.glmer <-glmer(rdi ~ Days + (1| Subject), data = sleepstudy, family =binomial(link ="logit"))
Generating predicted probabilities for each unit
## Manualallsubjects <-unique(sleepstudy$Subject)for(i in1:nrow(sleepstudy)){ n <-as.character(sleepstudy$Subject[i]) sleepstudy$subjectRE[i] <-ranef(fit.glmer)$Subject[n, 1]}## XB like usual, but need to add random effectspy <-plogis(model.matrix(fit.glmer)%*%fixef(fit.glmer) + sleepstudy$subjectRE)## Compare to Automaticcbind(py, fitted(fit.glmer), predict(fit.glmer, type ="response"))[1:5,]
In your own research you might ask the following questions:
Are my observations independent? Do I have constant error variance?
If independent, you might be fine with a standard model
If worried about the error variance, you could be fine with implementing some type of robust standard errors. See Gary King’s video for guidance and section 8.5.1 of the course notes.
Alternatively, is there some grouping structure to my data?
What are the different levels?
Are observations repeated over time?
Large N, few T, generally considered panel data
Large T, fewer N, generally considered time series cross-sectional
Then, you might consider the following choices if you have a grouping structure:
Consider clustering standard errors by group in a standard model
Outcome of today is a function of the past outcome modified by new information. Consider including if you think past outcomes influence future outcomes.
\(\rho\) is an “autocorrelation” term such that \(|\rho| < 1\).
Problem: Unless \(\rho = 0\), correlation created between regressors and error term \(\rightarrow\) strict exogeneity violated \(\rightarrow\) Nickell Bias. In random effects models, \(y_{it-1}\) also correlated with any group-level effects \(\alpha_i\).
The researchers randomly sampled survey respondents based on a list from the FEC, which contained the names of anyone who gave $200 or more to a candidate in the two years prior to 2012. The sampling process was designed to focus on donation behavior to the 22 senators who sought reelection in 2013–selecting people who might donate or might be pursued for a donation by one of these senators. The idea was that this sample would represent the senators’ potential “donorate”. Each observation is a senator-donor dyad: with 22 incumbent senators running for reelection and 2815 respondents, there are approximately 61,930 dyads (observations). For each observation, the data contain variables that indicate whether or not a respondent donated to the senator and how much that donation was, as well as the respondent’s total donations. Senators are required to record donations above $200, but some senators voluntarily report donations below this amount. Therefore, the data may include some donation totals between 0 and $200.
Key Variables include:
donation: 1=made donation to senator, 0=no donation made
total_donation: Dollar amount of donation made by donor to Senator.
total_donation_all: Dollar amount of all FEC recorded donations made by this donor.
maxdon: Dollar amount of the donor’s largest donation.
numsens: Number of unique senators a donor gave to.
numdonation: Number of unique donations a donor gave.
peragsen: policy agreement, percent issue agreement between donor and senator
per2agchal: percent issue agreement between donor and the senator’s challenger
cook: Cook competitiveness score for the senator’s race. 1 = Solid Dem or Solid Rep; 2 = Likely Dem or Likely Rep; 3 = Leans Dem or Leans Rep; 4 = Toss Up
same_state: 1=donor is from senator’s state, 0=otherwise
sameparty: 1=self-identifies as being in the candidate’s party; 0 otherwise
matchcommf: 1=Senator committee matches donor’s profession as reported in FEC file; 0=otherwise
NetWorth: Donor’s self-estimated net worth. 1=less than 250k, 2=250-500k; 3=500k-1m; 4=1-2.5m; 5=2.5-5m; 6=5-10m; 7=more than 10m
IncomeLastYear: Donor’s household annual income in 2013. 1=less than 50k; 2=50-100k; 3=100-125k; 4=125-150k; 5=150-250k; 6=250-300k; 7=300-350k; 8=350-400k; 9=400-500k; 10=more than 500k
idfold2: Donor’s self-described political ideology. 0 = moderate; 1=somewhat conservative or somewhat liberal; 2=conservative or liberal; 3=very liberal or very conservative
terms: The number of terms a legislator has been in office
YearBorn: Donor’s year of birth.
Edsum: Donor’s self-described educational attainment. 1=less than high school; 2=high school; 3=some college; 4=2-year college degree; 5=4-year college degree; 6=graduate degree
ideologue2: 1=respondent suggested the candidate’s ideological position was “extremely important” or if the respondent attached more importance to this factor than to both whether the “candidate could affect my industry or work” and “I know the candidate personally”, 0=otherwise
IK2: 1=respondent suggested “I know the candidate personally” was “extremely important” or if the respondent attached more importance to this factor than to both whether the “candidate’s position on the issues is similar to mine” and “the candidate could affect my industry or work”, 0=otherwise
donor_id: donor respondent unique id (each respondent is in the data 22 times)
The data also include dummy variables for each senator (e.g., sendum1, sendum2)
Research Question: Does policy agreement motivate people to give to campaigns?
Conduct and present an analysis that can help answer the question.
Try on your own, then expand to see the authors’ approach.
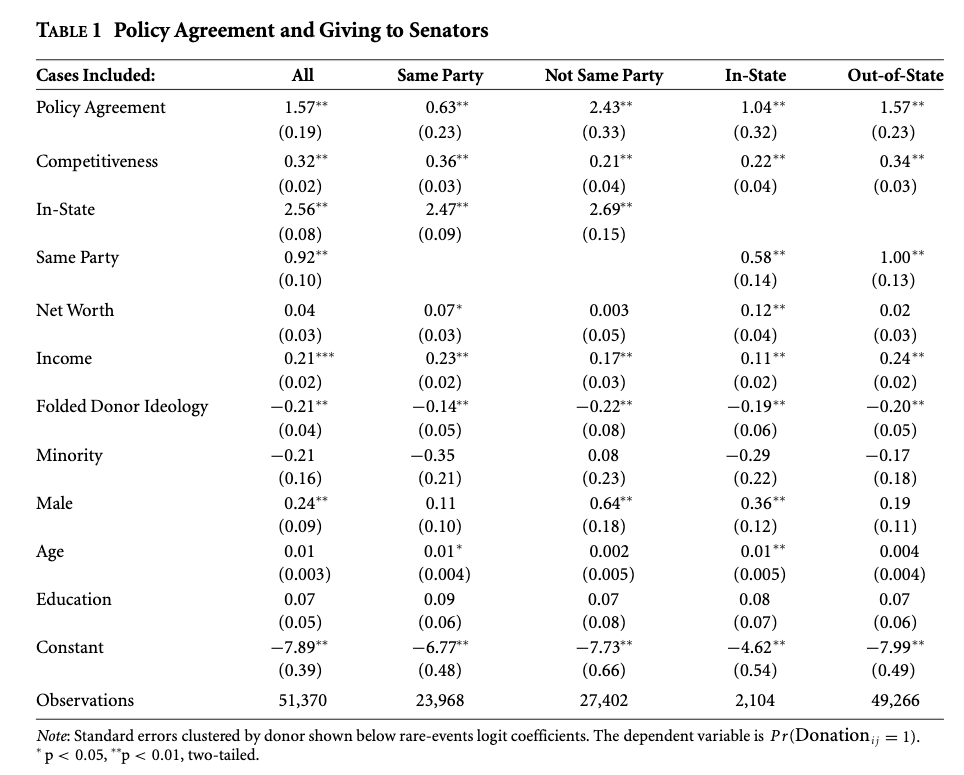
The authors use a “rare events logit” with clustered standard errors by donor “in order to account for the fact that the decision to give to a candidate may be correlated with decisions regarding other campaigns.” They also use a standard logistic regression as a robustness check in the appendix. They conduct an analysis among the full data, as well as theoretically interesting senator-respondent combinations.
For information on rare events logits, as a special form of the logit model, see here, a response here, and R code here.
They also analyze the amount given by transforming the variable into an incremental count outcome. “Because donations tend to be given in $50 increments, we use a rank-ordered variable that equals 0 for $0, 1 for $1–$49, 2 for $50–$99, and so on. Supplemental Table A9 shows that the results are robust to using the exact dollar amount, a rank based on $100 increments, and one based on $500 increments. Because donations are capped at $5,000, all of these dependent variables reflect this maximum. Moreover, as with the probability of donating, there is an overdispersion of zeros representing cases where a donor did not give to a senator. We accordingly use a zero-inflated negative binomial regression model for analyses of the amount donated. Additionally, for purposes of comparison, we show results for Tobit specifications.”
We discussed zero-inflated models in section Section 10
We can come up with several different possibles approaches, frequently using binary logistic regression with donation as the outcome or a linear model with total_donation as the outcome. Some may suggest specifications also included fixed effects for the donors using the plm package and fitting a within model. Finally, we explored using random effects in plm or lme4, though the lme4 approach appeared very stressful for our computers!
Here are a few approaches developed:
fit <-glm(donation ~ peragsen + terms + same_state + idfold2, data=don, family=binomial(link ="logit"))fit2 <-glm(donation ~ peragsen + cook + NetWorth + idfold2 + notwhite + malerespondent + terms,data=don, family=binomial(link ="logit"))fit3 <-glm(donation ~ peragsen + cook + NetWorth + idfold2 + notwhite + malerespondent + terms + sameparty,data=don, family=binomial(link ="logit"))library(plm)## remove missing data from the fixed effect to get plm to workdon2 <-subset(don, is.na(donor_id) ==F)fit5 <-plm(total_donation ~ peragsen, data = don2,model ="within",index =c("donor_id"))## random effectsfit6 <-plm(total_donation ~ peragsen, data = don2,model ="random",index =c("donor_id"))
We also discussed that one could use clustered standard errors like the authors after fitting a logistic regression model. Here is an example using fit3.