# Example of first 20 observations (Y1, Y2, ..., Y20)
1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 Binary Dependent Variables
In this section, we review models specifically designed for estimating the relationships between our independent variables and a dichotomous dependent variable. This is where “logit” and “probit” regression models become relevant.
Resources
These concepts are discussed in King, Gary. 1998. Unifying political methodology: The likelihood theory of statistical inference. University of Michigan Press. 5.1-5.3 (available through Rutgers online library)
The 2020 Gelman et al. book referenced in the syllabus also has a chapter devoted to logistic regression.
Key limitations of OLS in the binary case are discussed here, and will be referenced at the end of the section.
6.1 Data Generating Process
Let’s say \(Y_i\) is a set of 0’s and 1’s for whether two states have experienced a dispute, an outcome common in IR studies.
\[\begin{gather*} Y_i = \begin{cases}1, \;\text{a dispute happened}\\ 0,\; \text{a dispute did not happen}\end{cases} \end{gather*}\]- Outside of political science, for example, in the field of higher education, we might instead think about an outcome related to whether a student has (= 1) or has not (= 0) had a negative advising experience.
We need to align these data with a data generating process and distribution.
- For each \(Y_i\), it is like a single trial, where you have a dispute with some probability \((\pi)\)
- This sounds like the Bernoulli distribution! \(Y_i \sim Bernouli(\pi)\)
6.1.1 MLE Estimation
Let’s do the steps we saw in the previous section.
What is the data generating process? Based on this, describe the probability distribution for \(Y_i\).
- Note: if you are using a function like
glm()you can proceed directly there after this step. However, let’s work under the hood for a bit.
\[\begin{align*} Y_i \sim f(Y_i | \pi) &= Pr(Y_i = y_i |\pi_i) = \underbrace{\pi^{y_i}(1 -\pi)^{(1-y_i)}}_\text{pmf for Bernoulli} \end{align*}\] for \(y = 0,1\)
- Note: if you are using a function like
Define the likelihood for a single observation
Define the likelihood for all observations
Find the log-likelihood
Add step: nonlinear transformation to \(X\beta\)
Note that because we are likely using covariates, we need to express our parameter as a function of \(X\beta\). Why? Because we don’t think there is a constant probability for a dispute. Instead, we think the probability of a dispute varies according to different independent variables, which are included in the \(X\) matrix and everntually will each have their own \(\beta_k\) relationship with the probability of dispute.
- Now that we are outside of linear territory, we cannot just simply replace \(\pi\) with \(X\beta\) in the equation. Instead, \(\pi\) is a function of \(X\beta\). \(\pi = g(X_i, \beta) \neq \mathbf{x}_i'\beta\)
This is because we need a transformation, such as the logit or probit to map our linear predictor into the outcome to make sure the linear predictor can be transformed back into sensible units of the outcome. The logit is one variety, as is the probit. Like two roads diverged in a yellow wood, this is the point in the process where we choose the transformation. For this first example, let’s apply a logit transformation, which restricts our estimates to between 0 and 1 (a good thing for probability!) where:
\(\pi_i = \text{logit}^{-1}(\eta_i) = \frac{exp^{\eta_i}}{1 + exp^{\eta_i}} = \frac{exp^{\mathbf{x}_i'\beta}}{1 + exp^{\mathbf{x}_i'\beta}}\)
\(\eta_i = \text{logit}(\pi_i) = \log\frac{\pi_i}{1-\pi_i} = \mathbf{x}_i'\beta\)
- Maximize the function with respect to (wrt) \(\theta\)
Where \(\pi_i = \frac{exp^{\mathbf{x}_i'\beta}}{1 + exp^{\mathbf{x}_i'\beta}}\)
\[\begin{align*} \hat \pi &= \text{arg max } \ell( \pi | Y) \text{ wrt $\pi$} \\ &= \text{arg max} \sum_{i=1}^n\log \pi_i^{y_i}(1 -\pi_i)^{(1-y_i)}\\ &= \text{arg max} \sum_{i=1}^n \underbrace{y_i \log \Big( \frac{exp^{\mathbf{x}_i'\beta}}{1 + exp^{\mathbf{x}_i'\beta}}\Big) + (1-y_i)\log \Big(1-\frac{exp^{\mathbf{x}_i'\beta}}{1 + exp^{\mathbf{x}_i'\beta}}\Big)}_\text{We replaced $\pi_i$ and used the rule $\log a^b = b \log a$ to bring down the $y_i$ terms.} \end{align*}\]At this point, we take the derivative with respect to \(\beta\). You can try this on your own, and, if you’re lucky, it may show up on a problem set near you. With a bit of work, we should get something that looks like the below, which we can represent in terms of a sum or in matrix notation.
\[\begin{align*} S(\theta) &= \sum_{i=1}^n (Y_i - \pi_i)\mathbf{x}^T_i\\ &= X^T(Y - \mathbf{\pi}) \end{align*}\]You can note that the matrix notation retains the dimensions \(k \times 1\), which we would expect because we want to choose a set of \(k\) coefficients in our \(k \times 1\) vector \(\beta\). The score, as written in summation notation, also has length \(k\) but here, we use a convention as writing \(\mathbf{x}_i'\) in row vector representation instead of a column vector. You could instead represent this as multiplied by \(\mathbf{x}_i\), which would give us the \(k \times 1\) dimensions. Either way we have \(k\) coefficients. These are just different notations.
- Take the second derivative of the log likelihood to get the “hessian” and help estimate the uncertainty of the estimates. Again, we can represent this as a sum or in matrix notation, which might be easier when translating this into R code where our data is more naturally inside a matrix.
\[\begin{align*} H(\theta) &= - \sum_{i=1}^n \mathbf{x}_i\mathbf{x}^T_i(\pi_i)(1 - \pi_i)\\ &= -X^TVX \end{align*}\] where \(V\) is \(n \times n\) diagonal matrix with weights that are the ith element of \((\pi)(1 - \pi)\)
Once we have these quantities, we can optimize the function with an algorithm or go to glm in R, which will do that for us.
6.2 R code for fitting logistic regression
We can fit logistic regressions in R through glm(). Let’s build on the ANES example from section 5.3 and analyze a dichotomized measure of participation where 1=participated in at least some form and 0=did not participate.
anes <- read.csv("https://raw.githubusercontent.com/ktmccabe/teachingdata/main/anesdems.csv")
anes$partbinary <- ifelse(anes$participation > 0, 1, 0)We can then fit using glm where family = binomial(link="logit")
out.logit <- glm(partbinary ~ female + edu + age + sexism, data=anes,
family = binomial(link="logit"))The summary output includes the logit coefficients, standard errors, z-scores, and p-values.
summary(out.logit)
Call:
glm(formula = partbinary ~ female + edu + age + sexism, family = binomial(link = "logit"),
data = anes)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.5668 0.3328 0.4475 0.6287 1.2936
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.016734 0.334656 3.038 0.00238 **
female -0.382087 0.151516 -2.522 0.01168 *
edu 0.321190 0.050945 6.305 2.89e-10 ***
age 0.008682 0.004046 2.146 0.03188 *
sexism -1.593694 0.336373 -4.738 2.16e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1361.5 on 1584 degrees of freedom
Residual deviance: 1252.9 on 1580 degrees of freedom
(355 observations deleted due to missingness)
AIC: 1262.9
Number of Fisher Scoring iterations: 56.2.1 Writing down the regression model
In the articles you write, you will describe the methods you use in detail, including the variables in the model and the type of regression (e.g., logistic regression). Sometimes you may want to go a step further and be very explicit about the model that you ran. We’ve already seen the regression equations for linear models. For the GLMs, they will look very similar, but we need to make the link/response function an explicit part of the equation.
For example, for logistic regression we have a few ways of writing it, including:
- \(\log \frac{\pi_i}{1-\pi_i} = \mathbf{x_i'}\beta\), or alternatively
- \(Pr(Y_i = 1 | \mathbf{x}_i) = logit^{-1}(\mathbf{x}_i'\beta) = \frac{exp(\mathbf{x_i'}\beta)}{(1 + exp(\mathbf{x_i'}\beta)}\)
(You can also write out the individual variable names.) There is a new R package equatiomatic that can also be used to help write the equations from regression models. It’s not perfect, but should get you there for most basic models.
## First time, you need to install one of these
#remotes::install_github("datalorax/equatiomatic")
#install.packages("equatiomatic")
## Each time after, run library
library(equatiomatic)
## Will output in latex code, though see package for details on options
extract_eq(out.logit, wrap = TRUE, terms_per_line = 3)\[ \begin{aligned} \log\left[ \frac { P( \operatorname{partbinary} = \operatorname{1} ) }{ 1 - P( \operatorname{partbinary} = \operatorname{1} ) } \right] &= \alpha + \beta_{1}(\operatorname{female}) + \beta_{2}(\operatorname{edu})\ + \\ &\quad \beta_{3}(\operatorname{age}) + \beta_{4}(\operatorname{sexism}) \end{aligned} \]
6.3 Probit Regression
Probit regression is very similar to logit except we use a different link function to map the linear predictor into the outcome. Both the logit and probit links are suitable for binary outcomes with a Bernoulli distribution. If we apply a probit transformation, this also restricts our estimates to between 0 and 1.
- \(\pi_i = Pr(Y_i = 1| X_i) = \Phi(\mathbf{x}_i'\beta)\)
- \(\eta_i = \Phi^{-1}(\pi_i) = \mathbf{x}_i'\beta\)
Here, our coefficients \(\hat \beta\) represent changes in “probits” or changes “z-score” units. We use the Normal CDF (\(\Phi()\)) aka pnorm() in R to transform them back into probabilities, specifically, the probability that \(Y_i\) is 1.
Let’s fit our binary model with probit. We just need to change the link function.
We can then fit using glm where family = binomial(link="probit")
out.probit <- glm(partbinary ~ female + edu + age + sexism, data=anes,
family = binomial(link="probit"))Let’s apply the equation tool to this:
## Each time after, run library
library(equatiomatic)
## Will output in latex code, though see package for details on options
extract_eq(out.probit, wrap = TRUE, terms_per_line = 3)\[ \begin{aligned} P( \operatorname{partbinary} = \operatorname{1} ) &= \Phi[\alpha + \beta_{1}(\operatorname{female}) + \beta_{2}(\operatorname{edu})\ + \\ &\qquad\ \beta_{3}(\operatorname{age}) + \beta_{4}(\operatorname{sexism})] \end{aligned} \]
The summary output includes the probit coefficients, standard errors, z-scores, and p-values.
summary(out.probit)
Call:
glm(formula = partbinary ~ female + edu + age + sexism, family = binomial(link = "probit"),
data = anes)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.6343 0.3188 0.4470 0.6361 1.2477
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.603661 0.184864 3.265 0.00109 **
female -0.202300 0.083407 -2.425 0.01529 *
edu 0.179264 0.027611 6.493 8.44e-11 ***
age 0.005145 0.002257 2.280 0.02261 *
sexism -0.898871 0.186443 -4.821 1.43e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1361.5 on 1584 degrees of freedom
Residual deviance: 1250.6 on 1580 degrees of freedom
(355 observations deleted due to missingness)
AIC: 1260.6
Number of Fisher Scoring iterations: 5We can interepret the sign and significance of the coefficients similarly to OLS. They just aren’t in units of \(Y\). In the section next week, we will discuss in detail how to generate quantities of interest from this output.
6.4 To logit or to probit?
Both approaches produce a monotonically increasing S-curve in probability between 0 and 1, which vary according to the linear predictor (\(\mathbf{x_i}^T\beta\)). In this way, either approach satisfies the need to keep our estimates, when transformed, within the plausible range of \(Y\).
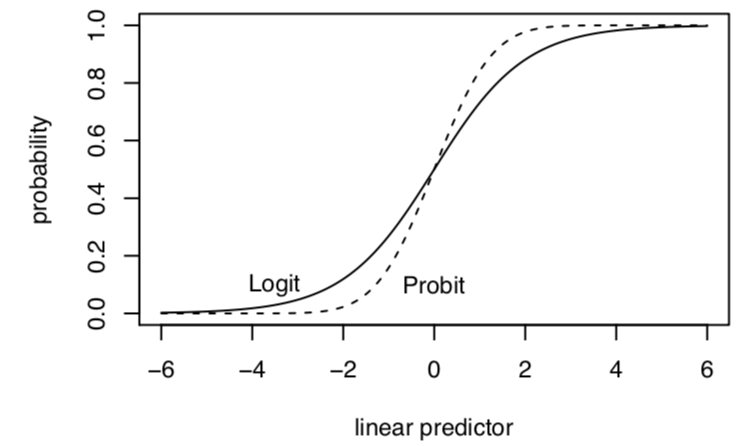 Image from Kosuke Imai.
Image from Kosuke Imai.
- Both also start with \(Y_i\) as bernoulli
- Both produce the same function of the log-likelihood BUT define \(\pi_i\) and link function differently
- Results–in terms of sign and significance of coefficients– are very similar
- Logit coefficients are roughly 1.6*probit coefficients
- Results–in terms of predicted probabilities– are very similar
- Exception– at extreme probabilities– Logit has “thicker tails”, gets to 0 and 1 more slowly
- Sometimes useful–Logit can also be transformed into “odds ratios”
- By convention, logit slightly more typically used in political science but easy enough to find examples of either
Note on Odds Ratios in Logistic Regression
Coefficients are in “logits” or changes in “log-odds” (\(\log \frac{\pi_i}{1 - \pi}\)). Some disciplines like to report “odds ratios”
- Odds ratio: \(\frac{\pi_i(x1)/(1 - \pi(x1))}{\pi_i(x0)/(1 - \pi(x0))}\) (at a value of x1 vs. x0)
- If \(\log \frac{\pi_i}{1 - \pi} = logodds\); \(\exp(logodds) = \frac{\pi_i}{1 - \pi}\)
- Therefore, if we exponentiate our coefficients, this represents an odds ratio: the odds of \(Y_i = 1\) increase by a factor of (\(\exp(\hat \beta_k)\)) due to 1-unit change in X
## odds ratio for the 4th coefficient
exp(coef(out.logit)[4]) age
1.00872 ## CI for odds ratios
exp(confint(out.logit)[4, ])Waiting for profiling to be done... 2.5 % 97.5 %
1.000790 1.016801 In political science, we usually opt to present predicted probabilities instead of odds ratios, but ultimately you should do whatever you think is best.
6.5 Latent propensity representation
Sometimes you will see the binary outcome problem represented as a latent propensity where \(Y^*_i\) is a continuous variable that represents an unobserved propensity (e.g., to have a dispute, to be a toxic tweet, to participate), where
\[\begin{gather*} Y_i = \begin{cases}1, \; y^*_i > \tau \\ 0,\; y^*_i \leq \tau \end{cases} \end{gather*}\]and \(\tau\) is some threshold after which a the event (e.g., dispute) occurs.
This becomes particularly relevant when the goal is to classify outcome estimates given certain \(X\) features. This type of threshold will also be relevant when we move into ordinal outcome variables where we want to estimate the probability an outcome belongs to a specific category.
6.6 Linear Probability Models
People (who me? yes, I admit, me) will sometimes still use a linear OLS model when we have dichotomous outcomes. In that case, we interpret the results as a “linear probability model” where a one-unit change in \(x\) is associated with a \(\hat \beta\) change in the probability that \(Y_i = 1\).
This may sound like a disaster because linear models are generally meant for nice continuous outcomes, and there is no way to prevent extreme values of \(X\beta\) from extending above 1 or below 0. This is not to mention the heteroskedasticity issues that come from binary outcome because the error terms depend on the values of \(X\). This website has a good overview of the potential problems with linear regression with binary outcomes.
 \
\
Image from Chelsea Parlett-Pelleriti @ChelseaParlett on Twitter
However, we can address some of these potential issues: 1) we can use robust standard errors to account for non-constant error variance , 2) if you look at the S-curve in the previous section, you will note that a large part of the curve is pretty linear over a wide range of \(X\beta\) values. For many applications, the estimates transformed from a logit or probit into probability will look similar to the estimates from a linear probability model (i.e., OLS). 3) Linear probability models are easier to interpret, and there is no need to transform coefficients.
LPM vs. logit/probit has spurred a lot of debate throughout the years. Reviewers disagree, twitter users disagree, some people just like to stir the pot, etc. This is just something to be aware of as you choose modeling approaches. Particularly when it comes to experiments and other causal inference approaches, there is a non-trivial push among active scholars to stick with linear probability models when your key independent variable is a discrete treatment indicator variable. See this new article from Robin Gomilla who lays out the considerations for using LPM, particularly in experimental settings, as well as follow up discussion from Andrew Gelman. That said, even if you run with an LPM and cite the Gomilla article, a reviewer may still ask you to do a logit/probit. And there are certainly circumstances where LPM will fall short. So what’s the upshot? Probably try both, and then choose your own adventure.
6.7 Binary Models in R Tutorial
This week’s example, we will replicate a portion of “The Effectiveness of a Racialized Counterstrategy” by Antoine Banks and Heather Hicks, published in the American Journal of Political Science in 2018. The replication data are here.
Abstract: Our article examines whether a politician charging a political candidate’s implicit racial campaign appeal as racist is an effective political strategy. According to the racial priming theory, this racialized counterstrategy should deactivate racism, thereby decreasing racially conservative whites’ support for the candidate engaged in race baiting. We propose an alternative theory in which racial liberals, and not racially conservative whites, are persuaded by this strategy. To test our theory, we focused on the 2016 presidential election. We ran an experiment varying the politician (by party and race) calling an implicit racial appeal by Donald Trump racist. We find that charging Trump’s campaign appeal as racist does not persuade racially conservative whites to decrease support for Trump. Rather, it causes racially liberal whites to evaluate Trump more unfavorably. Our results hold up when attentiveness, old-fashioned racism, and partisanship are taken into account. We also reproduce our findings in two replication studies.
We will replicate the analysis in Table 1 of the paper, based on an experiment the authors conducted through SSI. They exposed white survey respondents to either a news story about a Trump ad that includes an “implicit racial cue” or conditions that add to this with “explicitly racial” responses from different partisan actors calling out the ad as racist. Drawing on racial priming theory, racially prejudiced whites should be less supportive of Trump after the racial cues are made explicit. The authors test this hypothesis against their own hypothesis that this effect should be more pronounced among “racially liberal” whites.
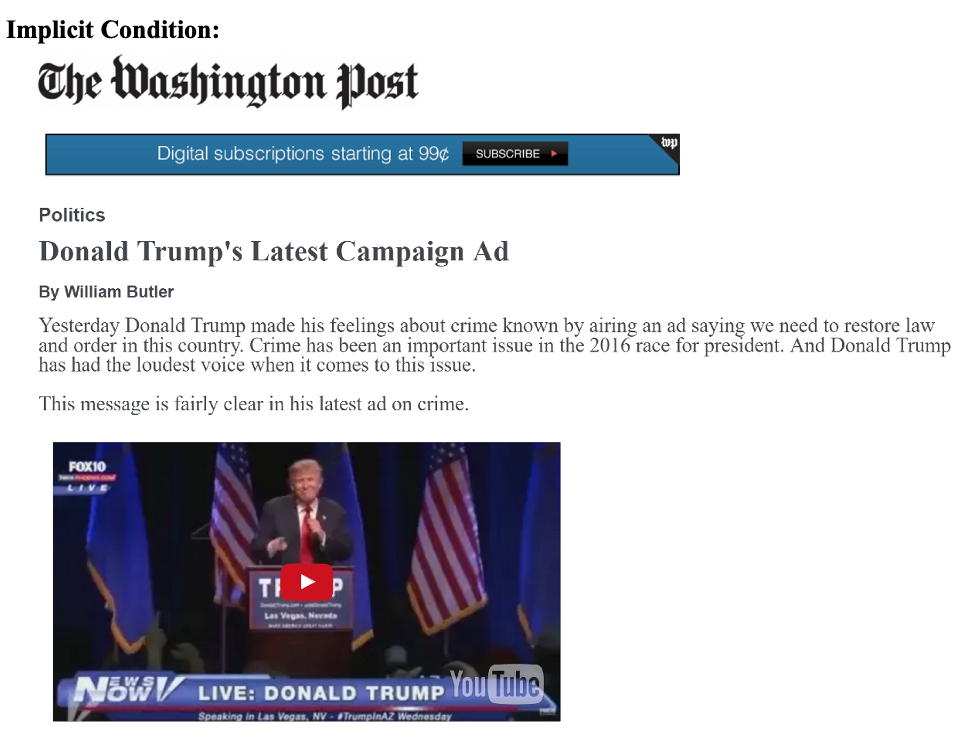
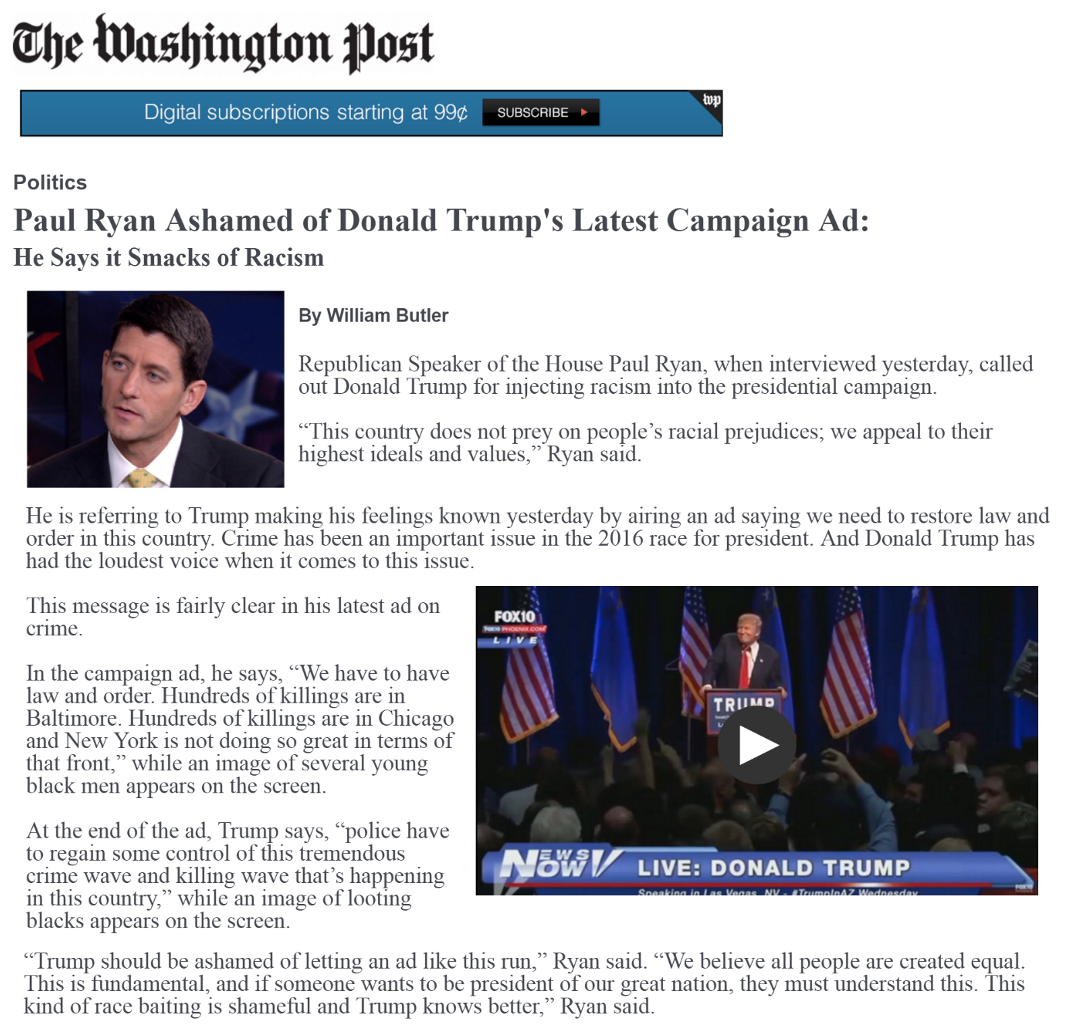
We are going to focus on a secondary outcome related to whether respondents believed the ad to be about race: “We also suspect that whites should provide a justification for either maintaining or decreasing their support for the candidate alleged to be playing the race card. Our results support these expectations. For example, racial liberals who read about a politician calling Trump’s implicit ad racist are more likely than those in the implicit condition to believe Trump’s ad is about race. On the other hand, pointing out the racial nature of the ad does not cause resentful whites to be any more likely to believe the ad is about race. Racially resentful whites deny that Trump’s subtle racial appeal on crime is racially motivated, which provides them with the evidence they need to maintain their support for his presidency” (320).
6.7.1 Loading data and fitting glm
Let’s load the data.
library(rio)
study <- import("https://github.com/ktmccabe/teachingdata/blob/main/ssistudyrecode.dta?raw=true")The data include several key variables
abtrace1: 1= if the respondent thought the ad was about race. 0= otherwisecondition2: 1= respondent in the implicit condition. 2= respondent in one of four explicit racism conditions.racresent: a 0 to 1 numeric variable measuring racial resentmentoldfash: a 0 to 1 numeric variable measuring “old-fashioned racism”trumvote: 1= respondent has vote preference for Trump 0=otherwise
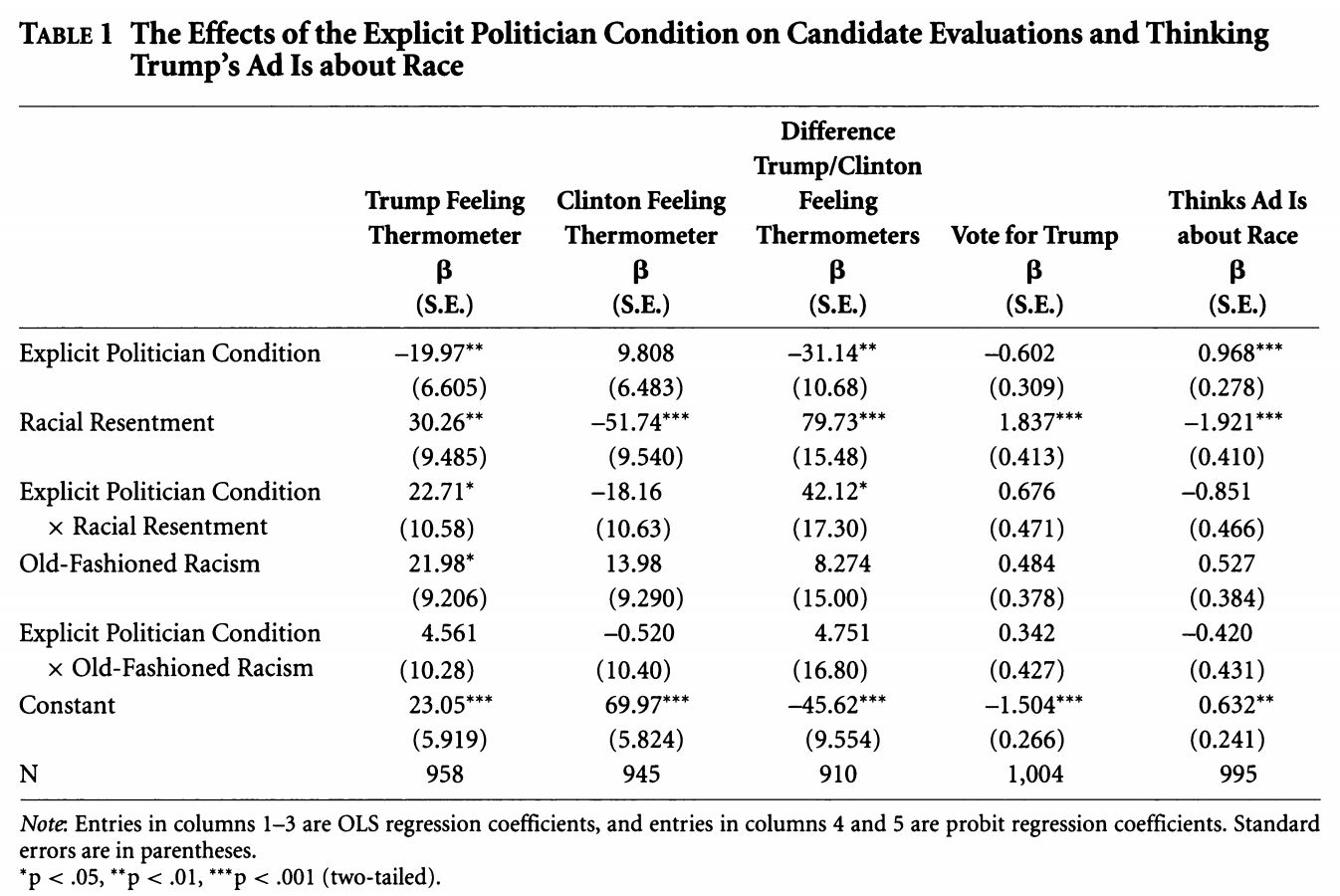
Let’s try to replicate column 5 in Table 1 using probit regression, as the authors do.
- Write down the equation for the regression.
- Use
glmto run the regression. - Compare the output to the table, column 5.
Try on your own, then expand for the solution.
We are fitting a probit regression.
## Column 5
fit.probit5 <- glm(abtrace1 ~ factor(condition2)*racresent + factor(condition2)*oldfash,
data=study, family=binomial(link = "probit"))
summary(fit.probit5)
Call:
glm(formula = abtrace1 ~ factor(condition2) * racresent + factor(condition2) *
oldfash, family = binomial(link = "probit"), data = study)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.2659 -0.9371 -0.5194 1.0015 2.0563
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.6320 0.2431 2.600 0.009323 **
factor(condition2)2 0.9685 0.2797 3.462 0.000535 ***
racresent -1.9206 0.4174 -4.601 4.2e-06 ***
oldfash 0.5265 0.3907 1.348 0.177772
factor(condition2)2:racresent -0.8513 0.4728 -1.801 0.071777 .
factor(condition2)2:oldfash -0.4197 0.4376 -0.959 0.337476
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1376.9 on 994 degrees of freedom
Residual deviance: 1148.7 on 989 degrees of freedom
(25 observations deleted due to missingness)
AIC: 1160.7
Number of Fisher Scoring iterations: 4We can write the regression as: \[\begin{align*} Pr(Y_i = 1 | X) &= \\ \Phi(\alpha + \text{Explicit Politician Condition}_i*\beta_1 +\\ \text{Racial Resentment}_i *\beta_2 +\\ \text{Old Fashioned Racism}_i*\beta_3 +\\ \text{Explicit Politician Condition}_i*\text{Racial Resentment}_i*\beta_4 +\\ \text{Explicit Politician Condition}_i* \text{Old Fashioned Racism}_i*\beta_5) \end{align*}\]
library(equatiomatic)
extract_eq(fit.probit5, wrap = TRUE, terms_per_line = 3)\[ \begin{aligned} P( \operatorname{abtrace1} = \operatorname{1} ) &= \Phi[\alpha + \beta_{1}(\operatorname{factor(condition2)}_{\operatorname{2}}) + \beta_{2}(\operatorname{racresent})\ + \\ &\qquad\ \beta_{3}(\operatorname{oldfash}) + \beta_{4}(\operatorname{factor(condition2)}_{\operatorname{2}} \times \operatorname{racresent}) + \beta_{5}(\operatorname{factor(condition2)}_{\operatorname{2}} \times \operatorname{oldfash})] \end{aligned} \]
A few questions:
- How should we interpret the coefficients?
- How do the interactions affect this interpretation?
6.7.2 Numeric Optimization
Let’s repeat our replication of column 5, but this time, let’s use numeric optimization. We first need to make an X and Y matrix from our data. Because we have already run the models, let’s use a trick below:
X <- model.matrix(fit.probit5)
Y <- as.matrix(fit.probit5$y)The next thing we need to do is make a function for the log likelihood. Let’s recall the log likelihood for a Bernoulli random variable from a previous section:
\[\begin{align*} \mathcal L( \pi | Y_i) &= \underbrace{\pi^{y_i}(1 -\pi)^{(1-y_i)}}_\text{Likelihood for single observation}\\ \mathcal L( \pi | Y) &= \underbrace{\prod_{i=1}^n\pi^{y_i}(1 -\pi)^{(1-y_i)}}_\text{Likelihood for all observations}\\ \ell( \pi | Y) &= \underbrace{\sum_{i=1}^n\log \pi^{y_i}(1 -\pi)^{(1-y_i)}}_\text{Log likelihood} \end{align*}\]Now we just change the definition of \(\pi\) to be the transformation for a probit, which is \(\Phi(X\beta)\). We code this up as a function below. Try to make the connection between the log likelihood equation above and the last line of the function. Note: in R, we can use pnorm() to express \(\Phi(X\beta)\), this is the CDF of the normal distribution.
llik.probit <- function(par, Y, X){
beta <- as.matrix(par)
link <- pnorm(X %*% beta)
like <- sum(Y*log(link) + (1 - Y)*log(1 - link))
return(like)
}Let’s generate some starting values for the optimization.
## Starting values
ls.lm <- lm(Y ~ X[, -1])
start.par <- ls.lm$coefFinally, let’s use optim to find our parameter estimates.
## optim()
out.opt <- optim(start.par, llik.probit, Y=Y,
X=X, control=list(fnscale=-1), method="BFGS",
hessian = TRUE)We can compare the estimates recovered from glm and optim.
## Log likelihood
logLik(fit.probit5)
out.opt$value'log Lik.' -574.3267 (df=6)
[1] -574.3267## Coefficients
cbind(round(coef(fit.probit5), digits=4),
round(out.opt$par, digits = 4)) [,1] [,2]
(Intercept) 0.6320 0.6321
factor(condition2)2 0.9685 0.9684
racresent -1.9206 -1.9207
oldfash 0.5265 0.5265
factor(condition2)2:racresent -0.8513 -0.8512
factor(condition2)2:oldfash -0.4197 -0.4196How could we get the standard errors?
6.7.3 Predicted Probabilities
One thing we could do for our interpretations is to push this further to generate “quantities of interest.”
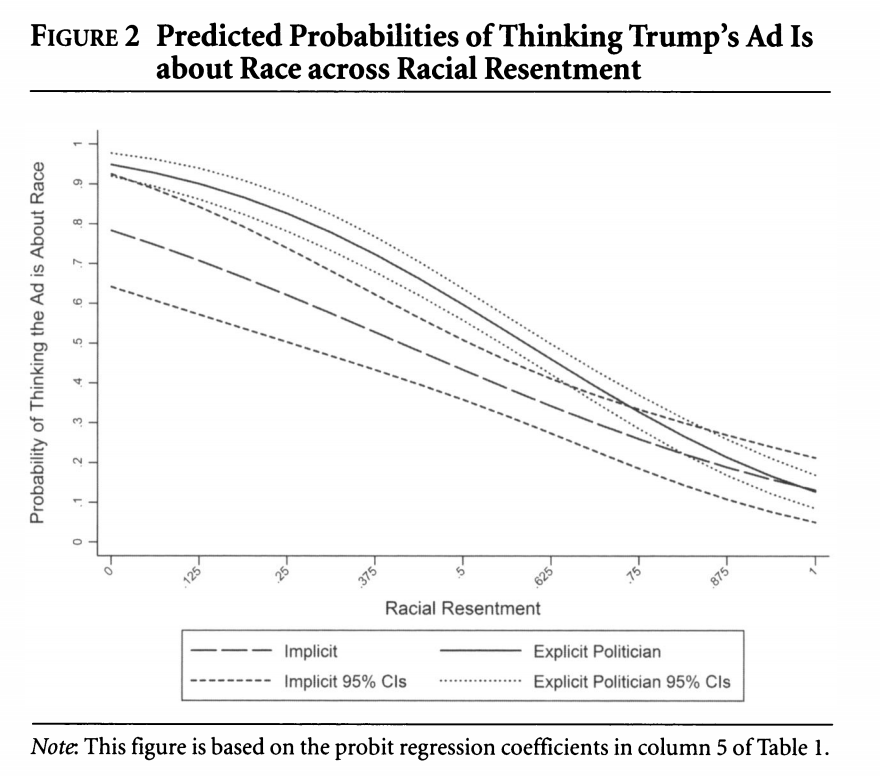
We will do one example of this but will talk in more detail about this next week. Let’s generate predicted probabilities for thinking the ad is about race across levels of racial resentment in the sample, for people in the implicit and explicit conditions. For this example, we are going to hold “old-fashioned racism” at its mean value. This is slightly different from what the authors do but should generate similar results. The authors hold old-fashioned racism at its “observed values.”
We can rely on the predict function like we did with OLS, but here, we need to set type = response to put the results on the response scale instead of the scale of the linear predictor. What this does is apply our function \(\Phi(\mathbf{x_i}' \hat \beta)\) for our designated values of \(X\) and estimates for \(\hat \beta\).
predvals.imp <- predict(fit.probit5, newdata = data.frame(condition2=1,
racresent = seq(0, 1, .0625),
oldfash = mean(study$oldfash, na.rm=T)),
type="response")
predvals.exp <- predict(fit.probit5, newdata = data.frame(condition2=2,
racresent = seq(0, 1,.0625),
oldfash = mean(study$oldfash, na.rm=T)),
type="response")
## Plot results
plot(x=seq(0, 1, .0625), y=predvals.imp, type="l",
ylim = c(0, 1), lty=2,
ylab = "Predicted Probability",
xlab = "Racial Resentment",
main = "Predicted Probability of Viewing the Ad as about Race",
cex.main = .7)
legend("bottomleft", lty= c(2,1), c("Implicit", "Explicit"))
points(x=seq(0, 1, .0625), y=predvals.exp, type="l")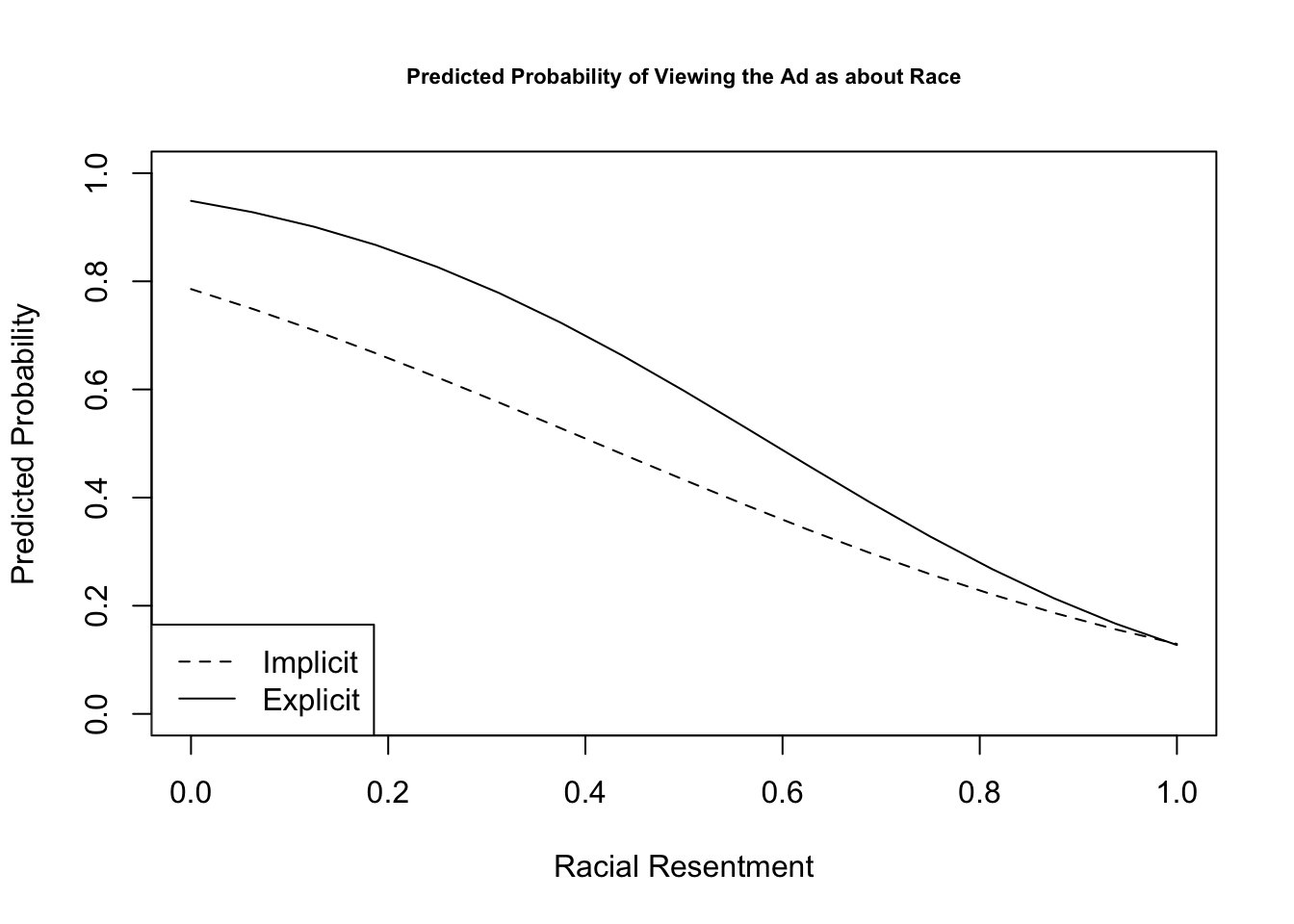
Additional Questions
- For extra practice, you can try replicating column 4 in the model.
- You can also try replicating the results in the figure with a logit model. Are the predicted probabilities similar?