install.packages("sotu", dependencies = TRUE)
install.packages("dplyr", dependencies = TRUE)
install.packages("tidytext", dependencies = TRUE)
install.packages("quanteda", dependencies = TRUE)
install.packages("wordcloud", dependencies = TRUE)
install.packages("SnowballC", dependencies = TRUE)11 Text as Data
Recall that we said, four primary goals of social science include:
- Describe and measure
- Has the U.S. population increased?
- Explain, evaluate, and recommend (study of causation)
- Does expanding Medicaid improve health outcomes?
- Predict
- Who will win the next election?
- Discover
- How do policies diffuse across states?
In this section, we start to explore the goal of discovery, seeing what we can learn from text as data.
11.1 Why text?
Words (can) matter. Patterns of word usage can be suggestive of deeper divides.

Article from Deadspin

Article from NY Times
Why Use R to analyze text?
- Assist in reading large amounts of text


- Efficiently summarize text through quantifying text attributes
- (Can) remove some subjectivity in coding text, allow to discover aspects of text unknown a priori
11.2 R Packages for text
Packages are like apps on your phone. They give you additional functionality. To use the tools in a package you first have to install it.
After you install it, just like on a phone, anytime you want to use the app, you need to open it. In R, we do that with library().
library(sotu)
library(dplyr)
library(tidytext)
library(quanteda)
library(wordcloud)
library(SnowballC)11.3 Application: State of the Union
The sotu package includes a dataset with the text of every U.S. State of the Union speech. It also includes second dataset with information about the speech. When datasets are stored in a package, you can add them to your environment through the data() function.
data(sotu_meta)
data(sotu_text)We are going to “bind” these together into a new dataframe. That way, the sotu_text is a variable inside of our speeches dataframe.
# Combine metadata and text
speeches <- cbind(sotu_meta, text=sotu_text)
speeches$doc_id <- speeches$X # make an id for each row
# SOTU speeches
range(speeches$year)[1] 1790 202011.3.1 Cleaning Text
Note that when working with raw text data, we usually do want our variables to be character variables and not factor variables. Here, every cell is not a category. Instead, it is a speech!
class(speeches$text)[1] "character"Text is messy data. We may want to spruce it up a bit by removing some of the non-essential characters and words, and moving everything to lowercase.
## Example of speech
speeches$text[1][1] "Fellow-Citizens of the Senate and House of Representatives: \n\nI embrace with great satisfaction the opportunity which now presents itself of congratulating you on the present favorable prospects of our public affairs. The recent accession of the important state of North Carolina to the Constitution of the United States (of which official information has been received), the rising credit and respectability of our country, the general and increasing good will toward the government of the Union, and the concord, peace, and plenty with which we are blessed are circumstances auspicious in an eminent degree to our national prosperity.\n\nIn resuming your consultations for the general good you can not but derive encouragement from the reflection that the measures of the last session have been as satisfactory to your constituents as the novelty and difficulty of the work allowed you to hope. Still further to realize their expectations and to secure the blessings which a gracious Providence has placed within our reach will in the course of the present important session call for the cool and deliberate exertion of your patriotism, firmness, and wisdom.\n\nAmong the many interesting objects which will engage your attention that of providing for the common defense will merit particular regard. To be prepared for war is one of the most effectual means of preserving peace.\n\nA free people ought not only to be armed, but disciplined; to which end a uniform and well-digested plan is requisite; and their safety and interest require that they should promote such manufactories as tend to render them independent of others for essential, particularly military, supplies.\n\nThe proper establishment of the troops which may be deemed indispensable will be entitled to mature consideration. In the arrangements which may be made respecting it it will be of importance to conciliate the comfortable support of the officers and soldiers with a due regard to economy.\n\nThere was reason to hope that the pacific measures adopted with regard to certain hostile tribes of Indians would have relieved the inhabitants of our southern and western frontiers from their depredations, but you will perceive from the information contained in the papers which I shall direct to be laid before you (comprehending a communication from the Commonwealth of Virginia) that we ought to be prepared to afford protection to those parts of the Union, and, if necessary, to punish aggressors.\n\nThe interests of the United States require that our intercourse with other nations should be facilitated by such provisions as will enable me to fulfill my duty in that respect in the manner which circumstances may render most conducive to the public good, and to this end that the compensation to be made to the persons who may be employed should, according to the nature of their appointments, be defined by law, and a competent fund designated for defraying the expenses incident to the conduct of foreign affairs.\n\nVarious considerations also render it expedient that the terms on which foreigners may be admitted to the rights of citizens should be speedily ascertained by a uniform rule of naturalization.\n\nUniformity in the currency, weights, and measures of the United States is an object of great importance, and will, I am persuaded, be duly attended to.\n\nThe advancement of agriculture, commerce, and manufactures by all proper means will not, I trust, need recommendation; but I can not forbear intimating to you the expediency of giving effectual encouragement as well to the introduction of new and useful inventions from abroad as to the exertions of skill and genius in producing them at home, and of facilitating the intercourse between the distant parts of our country by a due attention to the post-office and post-roads.\n\nNor am I less persuaded that you will agree with me in opinion that there is nothing which can better deserve your patronage than the promotion of science and literature. Knowledge is in every country the surest basis of public happiness. In one in which the measures of government receive their impressions so immediately from the sense of the community as in ours it is proportionably essential.\n\nTo the security of a free constitution it contributes in various ways - by convincing those who are intrusted with the public administration that every valuable end of government is best answered by the enlightened confidence of the people, and by teaching the people themselves to know and to value their own rights; to discern and provide against invasions of them; to distinguish between oppression and the necessary exercise of lawful authority; between burthens proceeding from a disregard to their convenience and those resulting from the inevitable exigencies of society; to discriminate the spirit of liberty from that of licentiousness - cherishing the first, avoiding the last - and uniting a speedy but temperate vigilance against encroachments, with an inviolable respect to the laws.\n\nWhether this desirable object will be best promoted by affording aids to seminaries of learning already established, by the institution of a national university, or by any other expedients will be well worthy of a place in the deliberations of the legislature.\n\nGentlemen of the House of Representatives: \n\nI saw with peculiar pleasure at the close of the last session the resolution entered into by you expressive of your opinion that an adequate provision for the support of the public credit is a matter of high importance to the national honor and prosperity. In this sentiment I entirely concur; and to a perfect confidence in your best endeavors to devise such a provision as will be truly with the end I add an equal reliance on the cheerful cooperation of the other branch of the legislature.\n\nIt would be superfluous to specify inducements to a measure in which the character and interests of the United States are so obviously so deeply concerned, and which has received so explicit a sanction from your declaration. \n\nGentlemen of the Senate and House of Representatives: \n\nI have directed the proper officers to lay before you, respectively, such papers and estimates as regard the affairs particularly recommended to your consideration, and necessary to convey to you that information of the state of the Union which it is my duty to afford.\n\nThe welfare of our country is the great object to which our cares and efforts ought to be directed, and I shall derive great satisfaction from a cooperation with you in the pleasing though arduous task of insuring to our fellow citizens the blessings which they have a right to expect from a free, efficient, and equal government. GEORGE WASHINGTON\n"# break up the text by word
tokens <- unnest_tokens(tbl = speeches,
output = word,
input = text,
token = "words", # one-token-per-row format
to_lower = TRUE, # lowercase
strip_numeric = TRUE, # strip numbers
strip_punct = TRUE) # strip punctuation
head(tokens) X president year years_active party sotu_type doc_id word
1 1 George Washington 1790 1789-1793 Nonpartisan speech 1 fellow
2 1 George Washington 1790 1789-1793 Nonpartisan speech 1 citizens
3 1 George Washington 1790 1789-1793 Nonpartisan speech 1 of
4 1 George Washington 1790 1789-1793 Nonpartisan speech 1 the
5 1 George Washington 1790 1789-1793 Nonpartisan speech 1 senate
6 1 George Washington 1790 1789-1793 Nonpartisan speech 1 and## further clean the text
tokens <- subset(tokens, !word %in% stop_words$word) # remove stopwords
head(tokens) X president year years_active party sotu_type doc_id
1 1 George Washington 1790 1789-1793 Nonpartisan speech 1
2 1 George Washington 1790 1789-1793 Nonpartisan speech 1
5 1 George Washington 1790 1789-1793 Nonpartisan speech 1
7 1 George Washington 1790 1789-1793 Nonpartisan speech 1
9 1 George Washington 1790 1789-1793 Nonpartisan speech 1
11 1 George Washington 1790 1789-1793 Nonpartisan speech 1
word
1 fellow
2 citizens
5 senate
7 house
9 representatives
11 embrace## could also stem the words
#tokens$word <- wordStem(tokens$word, language = "en")Note: What you might consider non-essential could differ depending on your application. Maybe you want to keep numbers in your text, for example.
11.3.2 Word Frequency
We count the number of times each word appears in each speech and sort them in descending order.
## introducing some tidyverse tools %>%
token_counts <- tokens %>%
count(doc_id, word, sort = TRUE)
head(token_counts) doc_id word n
1 158 dollars 207
2 199 congress 204
3 158 war 201
4 122 government 164
5 58 mexico 158
6 190 federal 141Here are the most frequent words for the first and last speeches.
# Word frequencies for first and last speech
head(subset(token_counts, doc_id == 1), 10) doc_id word n
22830 1 public 5
31278 1 country 4
31279 1 government 4
31280 1 measures 4
31281 1 regard 4
31282 1 united 4
45218 1 affairs 3
45219 1 citizens 3
45220 1 free 3
45221 1 house 3head(subset(token_counts, doc_id == 240), 10) doc_id word n
566 240 american 36
1751 240 people 22
1950 240 america 21
1951 240 country 21
2168 240 americans 20
2444 240 administration 19
2719 240 tonight 18
3057 240 america's 17
3467 240 president 16
3987 240 world 15Note: these are somewhat generic words.
11.3.3 Wordcloud
We can create a wordcloud of these speeches. Note that you can add color to the wordcloud using the same col argument. You can also assign a vector of colors and indicate ordered.colors=T to make sure they show up according to the order of the colors you assign.
Sometimes you will get a warning message that not all words could fit. You can increase the size of your plotting window in RStudio or adjust the scale() argument, which is similar to our cex arguments in past plotting functions. Scale reflects the range of the size of the words.
first_speech <- subset(token_counts, doc_id == 1)
first_speech$colors <- ifelse(first_speech$word=="citizens", "red2", "black")
wordcloud(first_speech$word, first_speech$n, max.words = 20,
col=first_speech$colors,
ordered.colors = T,
scale=c(3.5, 0.25))
11.4 Word Importance
We use tf-idf (term frequency - inverse document frequency) as a way to pull out uniquely important/relevant words for a given character.
- Relative frequency of a term inversely weighted by the number of documents in which the term appears.
- Functionally, if everyone uses the word “know,” then it’s not very important for distinguishing characters/documents from each other.
- We want words that a speech used frequently, that other speeches use less frequently
tfidf <- token_counts %>%
bind_tf_idf(word, doc_id, n) %>%
arrange(desc(tf_idf))
# Most unique words in first and last speech
head(subset(tfidf, doc_id == 1), 10) doc_id word n tf idf tf_idf
91 1 intimating 1 0.002450980 5.480639 0.013432939
92 1 licentiousness 1 0.002450980 5.480639 0.013432939
164 1 discern 1 0.002450980 4.787492 0.011734048
229 1 inviolable 1 0.002450980 4.382027 0.010740261
260 1 derive 2 0.004901961 2.113343 0.010359525
261 1 persuaded 2 0.004901961 2.113343 0.010359525
339 1 cherishing 1 0.002450980 3.871201 0.009488238
340 1 comprehending 1 0.002450980 3.871201 0.009488238
341 1 novelty 1 0.002450980 3.871201 0.009488238
424 1 cool 1 0.002450980 3.534729 0.008663551head(subset(tfidf, doc_id == 240), 10) doc_id word n tf idf tf_idf
75 240 ellie 7 0.002564103 5.480639 0.014052920
87 240 sanctuary 10 0.003663004 3.688879 0.013512379
245 240 tony 6 0.002197802 4.787492 0.010521960
294 240 amy 5 0.001831502 5.480639 0.010037800
295 240 iain 5 0.001831502 5.480639 0.010037800
296 240 janiyah 5 0.001831502 5.480639 0.010037800
297 240 jody 5 0.001831502 5.480639 0.010037800
303 240 tonight 18 0.006593407 1.510347 0.009958332
586 240 hake 4 0.001465201 5.480639 0.008030240
587 240 ortiz 4 0.001465201 5.480639 0.008030240## wordcloud
first_speech_tfidf <- subset(tfidf, doc_id == 1)
wordcloud(first_speech_tfidf$word, first_speech_tfidf$tf_idf, max.words = 30,
scale=c(2.5, 0.25))
Instead of a wordcloud, we could also present results as barplots.
barplot(first_speech_tfidf$tf_idf[1:10],
cex.axis=.6,
names=first_speech_tfidf$word[1:10],
cex.names=.5,
main= "Most `Important' 1790 SOTU Words (tf-idf)",
horiz = T, # flips the plot
las=2,
xlim=c(0, .015))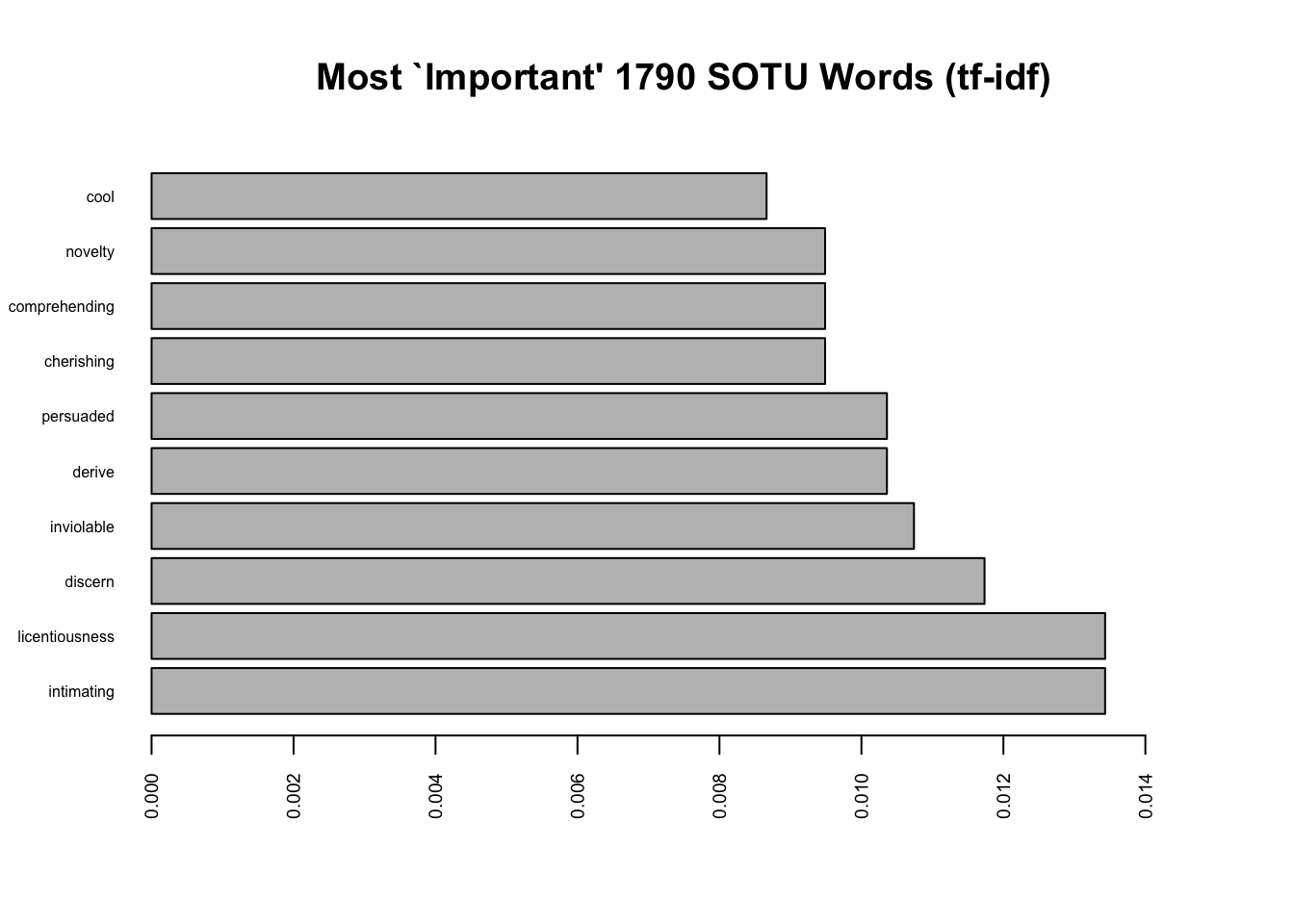
11.5 Document length
Are the length of speeches changing? The nchar() function tells you the number of characters in a “string.”
speeches$speechlength <- nchar(speeches$text)Let’s plot the length of speeches over time and annotate with informative colors and labels.
Is the length of speeches changing?
plot(x=1:length(speeches$speechlength), y= speeches$speechlength,
pch=15,
xaxt="n",
xlab="",
ylab = "Number of Characters")
## add x axis
axis(1, 1:length(speeches$speechlength), labels=speeches$year, las=3, cex.axis=.7)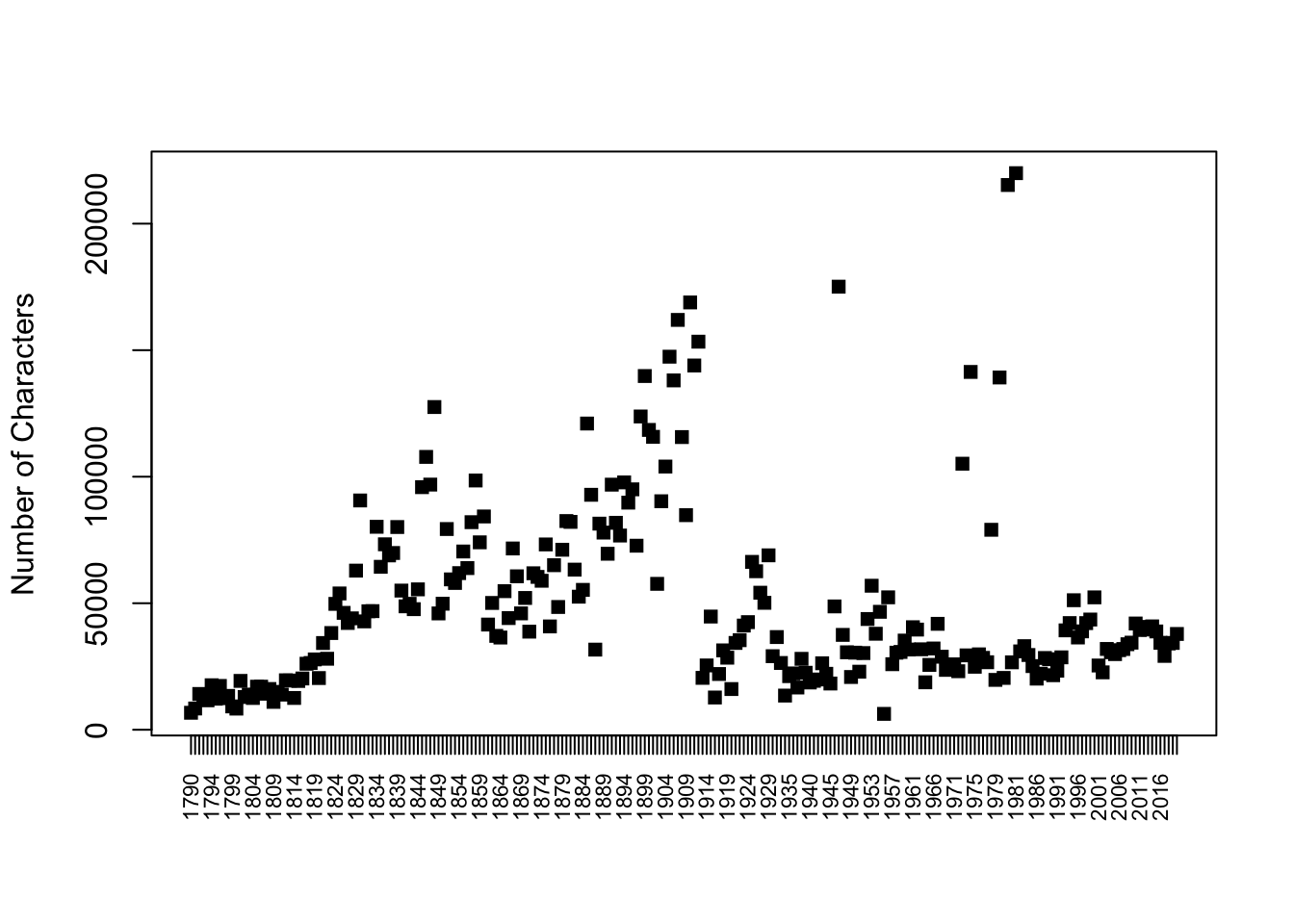
We can add color to distinguish written vs. spoken speeches
speechcolor <- ifelse(speeches$sotu_type == "written", "black", "green3")
plot(x=1:length(speeches$speechlength), y= speeches$speechlength,
xaxt="n", pch=15,
xlab="",
ylab = "Number of Characters",
col = speechcolor)
## add x axis
axis(1, 1:length(speeches$speechlength), labels=speeches$year, las=3, cex.axis=.7)
## add legend
legend("topleft", c("spoken", "written"),
pch=15,
col=c("green3", "black"), bty="n")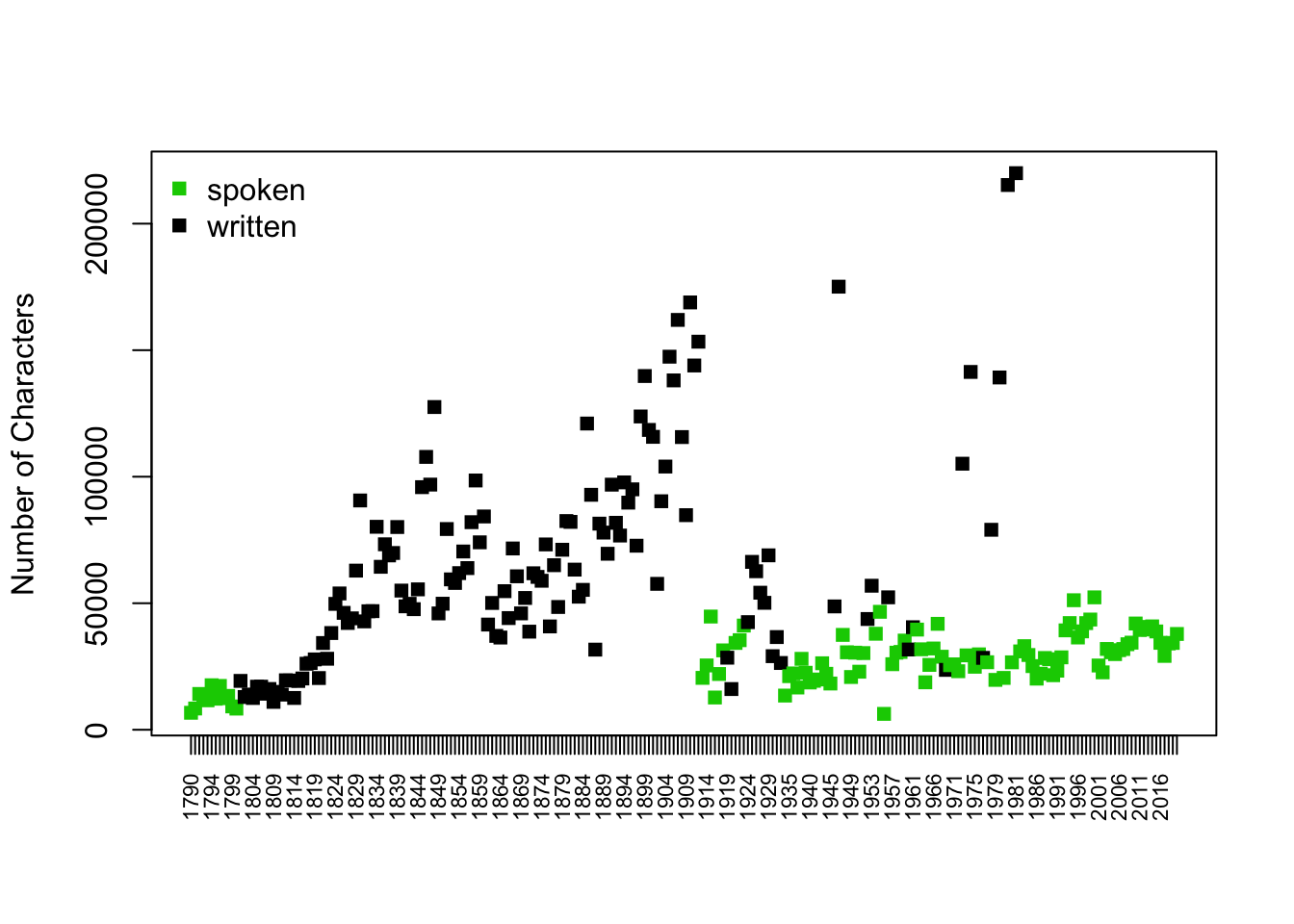
11.5.1 Counting tokens instead of characters
token_totals <- tapply(token_counts$n, token_counts$doc_id, sum)
# Convert to a data frame
token_totals <- data.frame(
doc_id = as.integer(names(token_totals)),
token_count = as.integer(token_totals)
)
speeches <- merge(speeches, token_totals, by = "doc_id", all.x = TRUE)speechcolor <- ifelse(speeches$sotu_type == "written", "black", "green3")
plot(x=1:length(speeches$token_count), y= speeches$token_count,
xaxt="n", pch=15,
xlab="",
ylab = "Number of Words",
col = speechcolor)
## add x axis
axis(1, 1:length(speeches$token_count), labels=speeches$year, las=3, cex.axis=.7)
## add legend
legend("topleft", c("spoken", "written"),
pch=15,
col=c("green3", "black"), bty="n")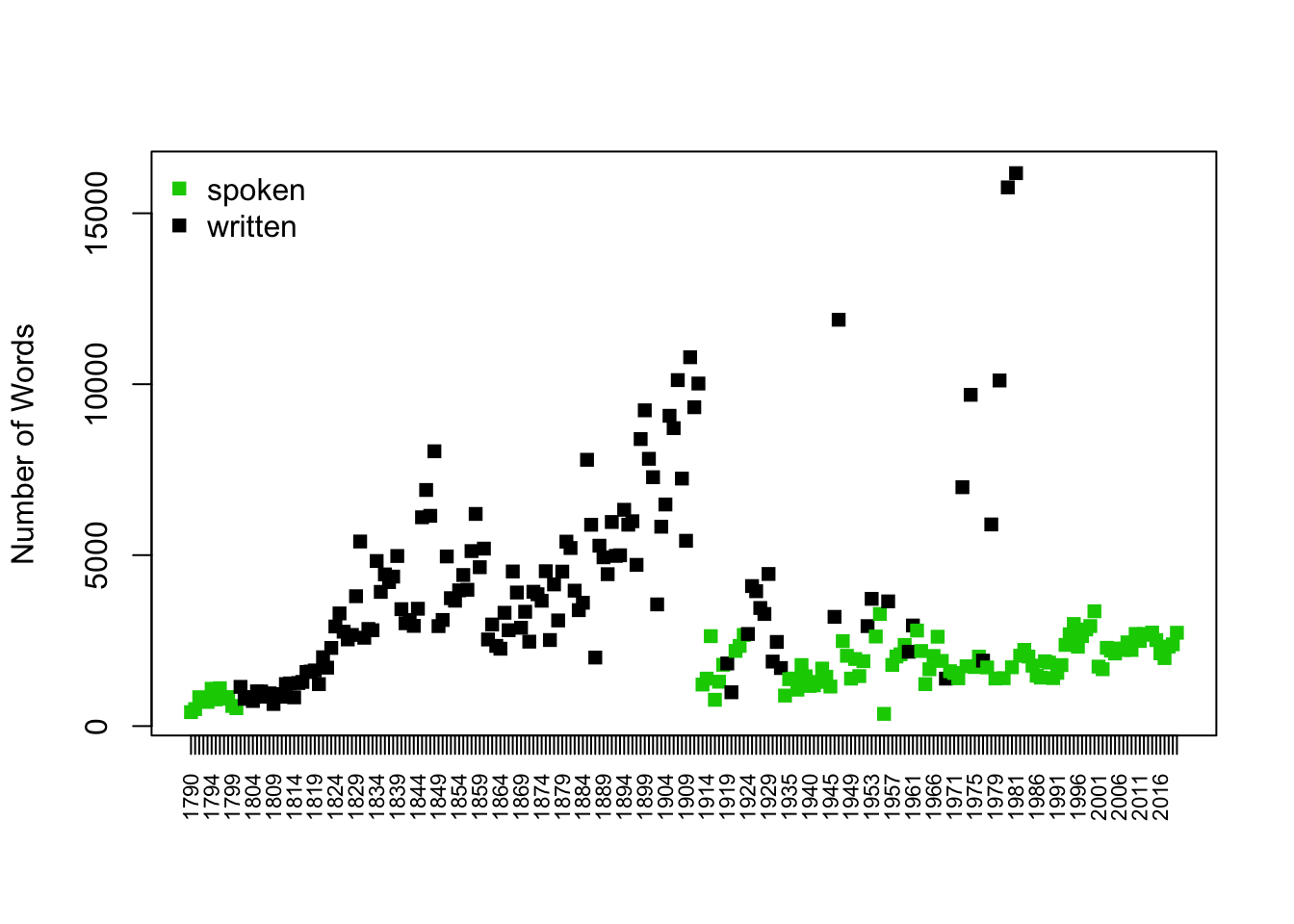
11.5.2 Hypothesis Tests
Can we test whether written speeches are significantly different in length from spoken speeches?
Null hypothesis: No difference in speech length
Can we reject the null?
t.speechlength <- t.test(speechlength ~ sotu_type, data=speeches)
t.speechlength
Welch Two Sample t-test
data: speechlength by sotu_type
t = -10.512, df = 158.83, p-value < 2.2e-16
alternative hypothesis: true difference in means between group speech and group written is not equal to 0
95 percent confidence interval:
-45385.33 -31028.20
sample estimates:
mean in group speech mean in group written
27815.75 66022.51 round(t.speechlength$p.value, digits=4)[1] 0What about a different hypothesis: Have speeches become shorter over time? For every one year increase, do we see an average decline in speech length?
Null hypothesis: No relationship, b=0
Can we reject the null? No!
fit <- lm(speechlength ~ year, data=speeches)
summary(fit)
Call:
lm(formula = speechlength ~ year, data = speeches)
Residuals:
Min 1Q Median 3Q Max
-43608 -24388 -11012 13329 170023
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 46024.017 68176.805 0.675 0.500
year 1.972 35.734 0.055 0.956
Residual standard error: 37060 on 238 degrees of freedom
Multiple R-squared: 1.28e-05, Adjusted R-squared: -0.004189
F-statistic: 0.003046 on 1 and 238 DF, p-value: 0.956Note that you can add multiple predictors to “control” on one variable while studying the relationship with others.
fit2 <- lm(speechlength ~ year + sotu_type, data=speeches)
summary(fit2)
Call:
lm(formula = speechlength ~ year + sotu_type, data = speeches)
Residuals:
Min 1Q Median 3Q Max
-65280 -14135 -3968 11846 128118
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -442623.81 66411.66 -6.665 1.84e-10 ***
year 241.11 34.01 7.090 1.53e-11 ***
sotu_typewritten 56814.80 4604.68 12.338 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 28980 on 237 degrees of freedom
Multiple R-squared: 0.3911, Adjusted R-squared: 0.386
F-statistic: 76.12 on 2 and 237 DF, p-value: < 2.2e-16Now that we control on speech type, we see that time is associated with a slight increase in length.
11.6 Dictionary Analysis
We can characterize the content of speeches in different ways. For example, we can see if speeches mention specific words, such as “terrorism.”
# Define a set of related terms
terror_terms <- c("terror", "terrorism", "terrorist",
"counterterror")
# Subset to just those tokens
terror_tokens <- subset(token_counts, word %in% terror_terms)Below we calculate sums. The first uses functions we have already covered in the course: tapply and data.frame.
# Count terrorism-related tokens per doc_id using tapply
terror_counts <- tapply(terror_tokens$n, terror_tokens$doc_id, sum)
head(terror_counts)29 62 79 86 95 96
1 1 1 1 1 1 We now create a data.frame. We did this recently in our prediction module. This just reformats our tapply output.
# Convert named vector to data frame
terror_counts <- data.frame(
doc_id = names(terror_counts),
terror_word_count = as.integer(terror_counts)
)
head(terror_counts) doc_id terror_word_count
1 29 1
2 62 1
3 79 1
4 86 1
5 95 1
6 96 1We can now merge this back in with our speeches data so that the information is attached to our original dataset.
# Merge with speeches
speeches <- merge(speeches, terror_counts, by = "doc_id", all.x = TRUE)Lastly, we have just a little cleanup. We want all of the speeches to have a number, so we have to replace any missing values with 0, indicating the absence of any “terrorism” word.
# Replace NA with 0 (docs that had none of those terms)
speeches$terror_word_count[is.na(speeches$terror_word_count)] <- 0Let’s look at the use of terrorism words by president.
sort(tapply(speeches$terror_word_count, speeches$president, sum),
decreasing=T)[1:10] George W. Bush William J. Clinton Donald Trump
94 16 14
Barack Obama Ronald Reagan Franklin D. Roosevelt
13 9 5
Lyndon B. Johnson Harry S Truman Jimmy Carter
4 3 3
Chester A. Arthur
2 What are possible limitations of this analysis?
12 In-Class Exercise: Choose your Own Adventure
12.1 Choose your own adventure
In this health check, pick and load the text as dataset of your choice to work with. Options include:
constitutions.csv: The data set contains the raw textual information about the preambles of constitutions around the world. We focus on the preamble of each constitution, which typically states the guiding purpose and principles of the rest of the constitution.country: The country nameyear: The year the constitution was createdpreamble: Raw text of the constitution’s preamble
- Beyonce lyrics: The dataset contains lyrics to many Beyonce songs at the “line level” (though was created in 2020, so is missing a few)
line: Contains the line of textsong_name: Contains the name of the song
- Taylor Swfit lyrics: The dataset contains the lyrics to many Taylor Swift songs.
lyric: Contains the line of texttrack_name: Contains the name of the trackalbum_name: Containes the name of the album
- Stranger Things dialogue: The data set contains dialogue from the show Stranger Things (dataset from 2023)
raw_text: Contains the line of dialogueseason_episode: Indicates which season and episode the dialogue comes fromepisdode,season: Separately indicates the episode number or season number
Let’s read in the data, load required packages. Verify that the text variable in your chosen dataset is a “character” variable and that you can see the text output of the first observation.
First, load some text packages
library(dplyr)
library(tidytext)
library(quanteda)
library(wordcloud)
library(SnowballC)## constitution
constitution <- read.csv("https://raw.githubusercontent.com/ktmccabe/teachingdata/main/constitution.csv")
constitution$doc_id <- 1:nrow(constitution) #make unique doc_id variable
class(constitution$preamble) # text variable[1] "character"constitution$preamble[1][1] "In the name of Allah, the Most Beneficent, the Most Merciful Praise be to Allah, the Cherisher and Sustainer of Worlds; and Praise and Peace be upon Mohammad, His Last Messenger and his disciples and followers We the people of Afghanistan: Believing firmly in Almighty God, relying on His divine will and adhering to the Holy religion of Islam; Realizing the previous injustices, miseries and innumerable disasters which have befallen our country; Appreciating the sacrifices, historical struggles, jihad and just resistance of all the peoples of Afghanistan, admiring the supreme position of the martyrs of the country's freedom; Comprehending that a united, indivisible Afghanistan belongs to all its tribes and peoples; Observing the United Nations Charter as well as the Universal Declaration of Human Rights; And in order to: Strengthen national unity, safeguard independence, national sovereignty and territorial integrity of the country; Establish an order based on the peoples' will and democracy; Form a civil society void of oppression, atrocity, discrimination as well as violence, based on rule of law, social justice, protecting integrity and human rights, and attaining peoples' freedoms and fundamental rights; Strengthen political, social, economic as well as defense institutions; Attain a prosperous life and sound living environment for all inhabitants of this land; And, eventually, regain Afghanistan's appropriate place in the international family; Have, herein, approved this constitution in accordance with the historical, cultural and social realities as well as requirements of time through our elected representatives in the Loya Jirga, dated January 3, 2004, held in the city of Kabul."## beyonce
beyonce <- read.csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-09-29/beyonce_lyrics.csv')
beyonce$doc_id <- 1:nrow(beyonce) #make unique doc_id variable
class(beyonce$line)[1] "character"beyonce$line[1][1] "If I ain't got nothing, I got you"taylor <- read.csv("https://raw.githubusercontent.com/ktmccabe/teachingdata/refs/heads/main/taylor.csv")
taylor$doc_id <- 1:nrow(taylor) #make unique doc_id variable
class(taylor$lyric)[1] "character"taylor$lyric[1][1] "He said the way my blue eyes shined"## stranger things
strangerthings <- read.csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2022/2022-10-18/stranger_things_all_dialogue.csv')
strangerthings$season_episode <- paste(strangerthings$season,
strangerthings$episode, sep = "_")
strangerthings$doc_id <- 1:nrow(strangerthings) #make unique doc_id variable
class(strangerthings$raw_text)[1] "character"strangerthings$raw_text[1][1] "[crickets chirping]"12.1.1 Problem 1
Let’s pre-process our texts to make them easier to analyze. Unnest the text by the unit of “words.” Remove punctuation and make lowercase. You can decide whether you want to remove numbers based on your use case. Store the results in an object called tokens. This is an arbitrary name but will help us all work together. You should use the unnest code from our course notes, but you likely have a different input column.
Report the 6 first words in the data by using head(tokens$word) after you unnest.
# break up the text by wordAfter creating the tokens object, further remove stop words by running the code here: tokens <- subset(tokens, !word %in% stop_words$word)
## further clean the text12.1.2 Problem 2
Word frequency. Count up the number of times each word is used in a given unit analysis of interest. This could be by the doc_id variable or some higher level of aggregation such as track_name,song_name or season_episode. Store these counts in an object called token_counts. And report head(token_counts)
## use the count function12.1.3 Problem 3
Wordclouds! Pick a particular subset of the token_counts to analyze. For example, you might pick a particular doc_id, track_name, etc.
# subset the data and then use wordcloud()12.1.4 Problem 4
Pick a topic to explore in your text. Create a vector of words that represent this topic. Sum up the number of times these words are used and merge them back into your dataset.
# create the vector of words
# subset the token counts data using subset() to only rows that have those words
# use tapply to sum up the words
# format as a dataframe
# merge back into your original dataset12.1.5 Extra if time
Conduct a t.test() to compare average mentions of the topic you chose across two different groups in your data. E.g., this could be across two different seasons of Stranger Things, different year ranges on constitutions data, different albums of songs, etc.
# t.test code here12.1.6 Example application
Try on your own, then expand for an example.
taylor <- read.csv("https://raw.githubusercontent.com/ktmccabe/teachingdata/refs/heads/main/taylor.csv")
taylor$doc_id <- 1:nrow(taylor) #make unique doc_id variable
class(taylor$lyric)[1] "character"taylor$lyric[1][1] "He said the way my blue eyes shined"# break up the text by word
tokens_taylor <- unnest_tokens(tbl = taylor,
output = word,
input = lyric,
token = "words", # one-token-per-row format
to_lower = TRUE, # lowercase
strip_numeric = TRUE, # strip numbers
strip_punct = TRUE) # strip punctuation
head(tokens_taylor$word)[1] "he" "said" "the" "way" "my" "blue"tokens_taylor <- subset(tokens_taylor, !word %in% stop_words$word)
token_counts_taylor <- tokens_taylor %>%
count(track_name, word, sort = TRUE)
head(token_counts_taylor) track_name word n
1 Red (Taylor's Version) red 107
2 I Did Something Bad di 81
3 Shake It Off (Taylor's Version) shake 70
4 Run (Taylor's Version) [From The Vault] run 52
5 This Love (Taylor's Version) love 52
6 We Are Never Ever Getting Back Together (Taylor's Version) ooh 50red_words <- subset(token_counts_taylor, track_name == "Red (Taylor's Version)")
red_words$colors_taylor <- ifelse(red_words$word=="red", "red3", "black")
wordcloud(red_words$word, red_words$n, max.words = 20,
colors =red_words$colors_taylor,
ordered.colors = TRUE,
random.color = FALSE,
random.order=FALSE,
scale=c(2.5, .25))
# create the vector of words
love <- c("love", "loving", "marry")
# subset the token counts data using subset() to only rows that have those words
love_taylor <- subset(token_counts_taylor, word %in% love)
# use tapply to sum up the words
love_taylor_counts <- tapply(love_taylor$n, love_taylor$track_name, sum)
# format as a dataframe
love_taylor_counts <- data.frame(
track_name = names(love_taylor_counts),
love_word_count = as.integer(love_taylor_counts)
)
# merge back into your original dataset
taylor <- merge(taylor, love_taylor_counts, by = "track_name", all.x = TRUE)
taylor$love_word_count[is.na(taylor$love_word_count)] <- 0
# t.test code here
taylor_track <- taylor %>% select(love_word_count, track_name, album_name)
taylor_track <- unique(taylor_track)
taylor_track <- subset(taylor_track, album_name %in% c("reputation", "1989 (Taylor's Version)"))
t.test(love_word_count ~ album_name, data=taylor_track)
Welch Two Sample t-test
data: love_word_count by album_name
t = 1.6345, df = 24.361, p-value = 0.115
alternative hypothesis: true difference in means between group 1989 (Taylor's Version) and group reputation is not equal to 0
95 percent confidence interval:
-1.011162 8.738698
sample estimates:
mean in group 1989 (Taylor's Version) mean in group reputation
5.130435 1.266667 13 Application Programming Interfaces
Application programming interfaces (APIs) are tools that allow you to search a large database to extract specific types of information. Social scientists often work with APIs to extract data from social media platforms, government agencies (e.g., U.S. Census), and news sites, among others.
Organizations that develop these APIs can control what types of information researchers can access. Often, they set limits on the types and quantities of information someone can collect. Companies also often monitor who accesses the information by requiring people to sign up for access, apply for access, and/or pay for access.
13.1 Example: Google Trends
Oftentimes, developers that use R will create “wrappers” for using APIs. These are R packages that have R-friendly functions for asking the API to extract information.
An example of one of these is the gtrendsR package which queries Google to understand the popularity of different topics using key word search terms.
We can install the R packages below. Remember, you only have to do the install line once.
We are going to install the development version of the package, which includes the most recent updates the package authors have made, which often happen prior to when they officially provide them to the R respository. To do this, we need the package devtools. Occasionally, this can create trouble for some computers. If you have trouble installing devtools, you can focus on other examples instead. This is not essential for the completion of the course.
install.packages("devtools")
install.packages("curl")devtools::install_github("PMassicotte/gtrendsR")Each time we use it, we need to use library()
library(gtrendsR)Now we have access. Note that most functions that let you extract information from websites, social media, etc., have what are called “rate limits” that limit the size and quantity of your calls for information. If you get an error when making a query, this might be what is happening.
13.1.1 Popularity of Side Dishes
To demonstrate how this works, we can ask for data on the popularity of “green bean casserole” and “mashed potatoes” in NJ.
The first line asks and stores this information
res <- gtrends(c("green bean casserole",
"mashed potatoes"), geo = c("US-NJ"))13.1.2 Saving R Objects
After you extract data from online, you may want to save them as a hard data file on your computer. This way if you close RStudio, you can reproduce the data.
R allows you to save any R object as an .RData file that can be opened with the load() command. This is discussed on pg. 24 of QSS Chapter 1.
We can demonstrate this now by saving res as an RData object. It will automatically save to your working directory, but you can also add a subfolder or alternative file path.
save(res, file = "sideresults.RData")Then, you can load the file (if you happen to close R/RStudio, restart your computer, etc.) with the load command.
load("sideresults.RData")We can take a look at the data we extracted. Trend results are re-scaled based on relative popularity, not absolute search volume.
head(res$interest_over_time) date hits keyword geo time gprop category
1 2020-11-22 61 green bean casserole US-NJ today+5-y web 0
2 2020-11-29 3 green bean casserole US-NJ today+5-y web 0
3 2020-12-06 2 green bean casserole US-NJ today+5-y web 0
4 2020-12-13 2 green bean casserole US-NJ today+5-y web 0
5 2020-12-20 11 green bean casserole US-NJ today+5-y web 0
6 2020-12-27 2 green bean casserole US-NJ today+5-y web 0And this line plots the results. The package has a built-in version of the R plot function.
plot(res)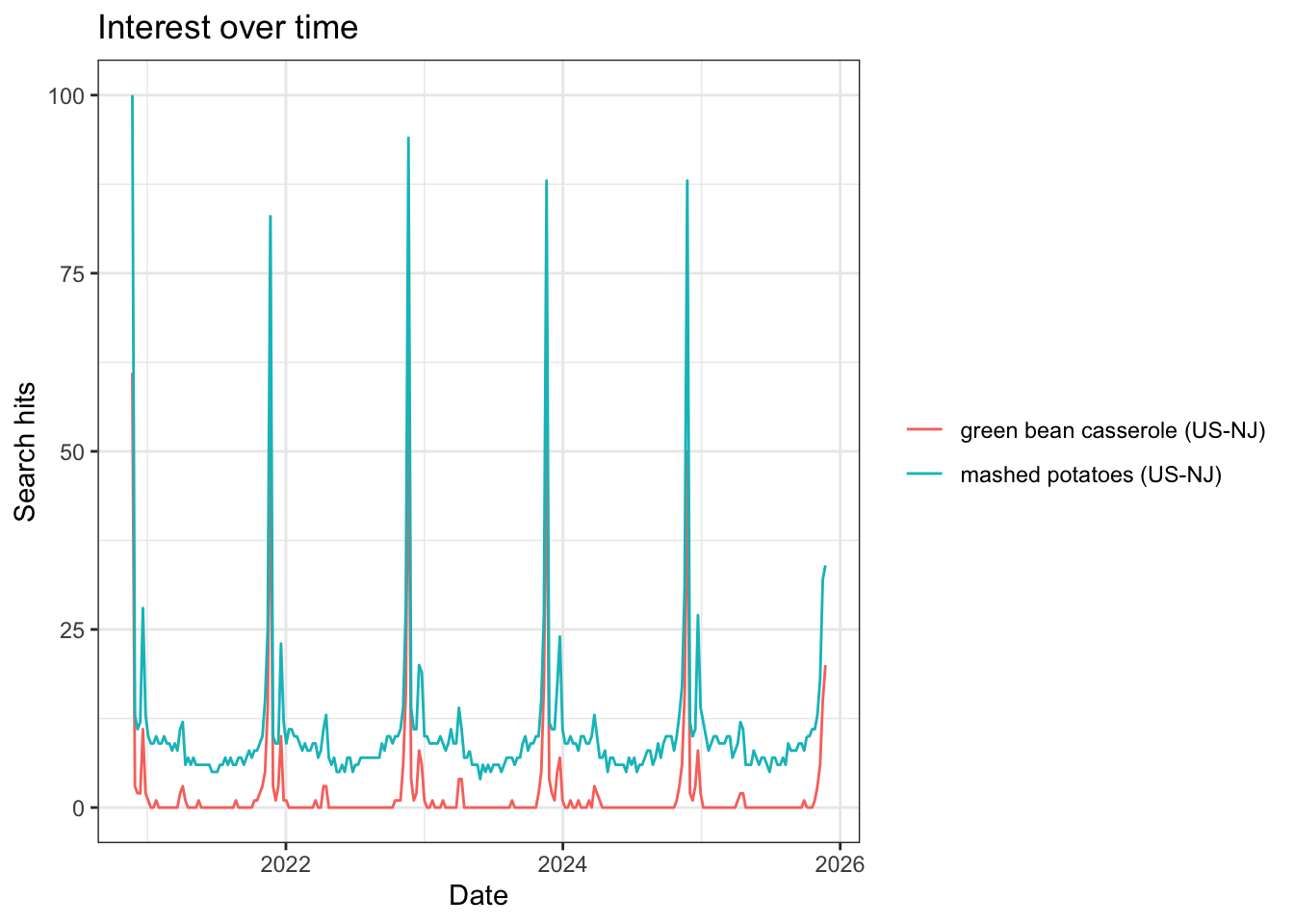
13.2 Perspective API
Another API that can be used with text as data is Google’s Perspective API. It uses statistical machine learning models based trained on real-world comments to score text on the likelihood it will be perceived as toxic. More information here: https://www.perspectiveapi.com/.
This, like many APIs, requires a “key” and “secret” to use. Think of these like passwords.We are going to use an R package that serves as a “wrapper” for the API, making it easier to access the API with R-friendly functions. The github for the package describes the steps you can personally take to set up a perspective API account. We will just use my account in class. https://github.com/favstats/peRspective?tab=readme-ov-file
We will use the development version of the package.
devtools::install_github("favstats/peRspective")We open the package below.
library(peRspective)From the package github documentation: “peRspective functions will read the API key from environment variable perspective_api_key. In order to add your key to your environment file, you can use the function edit_r_environ() from the usethis package. If your function does not work, you likely need to install usethis as a package first.”
usethis::edit_r_environ()“This will open your .Renviron file in your text editor. Now, you can add the following line to it:”
perspective_api_key="YOUR_API_KEY"Now you should be ready to use the main function, prsp_score which will score text based on the chance it would be perceived as toxic, among other dimensions of text sentiment/content.
For example, let’s pull two recent tweets from Vice President JD Vance to demonstrate variation in the scores:
jd1 <- "I have an extraordinary tolerance for disagreements and criticisms from the various people in our coalition. But I am a very loyal person, and I have zero tolerance for scumbags attacking my staff. And yes, *everyone* who I've seen attack Buckley with lies is a scumbag."
text_scores1 <- prsp_score(
text = jd1,
languages = "en",
score_model = peRspective::prsp_models
)
text_scores1$TOXICITY[1] 0.6599687jd2 <- "Today's jobs report shows that the Trump economic plan is working: 119,000 new jobs when economists thought we would only add 52,000.Wages are continuing to outpace inflation and manufacturing hours are increasing. We've got a lot more work to do, but these are great signs."
text_scores2 <- prsp_score(
text = jd2,
languages = "en",
score_model = peRspective::prsp_models)
text_scores2$TOXICITY[1] 0.01017851If we wanted to score several comments from a dataset, we could create a loop to repeat the function for each comment. Here is a short example creating our tweets as a dataframe first, and then storing toxicity scores in that dataset as a new column.
jddata <- data.frame(text=c(jd1, jd2), toxicity=NA)
for(i in 1:length(jddata$text)){
text_scores <- prsp_score(
text = jddata$text[i],
languages = "en",
score_model = peRspective::prsp_models)
jddata$toxicity[i] <- text_scores$TOXICITY
}
jddataWe can then save the output so we don’t have to re-score the data every time we use R.
save(jddata, file="jddata.RData")load("jddata.RData")
jddata text
1 I have an extraordinary tolerance for disagreements and criticisms from the various people in our coalition. But I am a very loyal person, and I have zero tolerance for scumbags attacking my staff. And yes, *everyone* who I've seen attack Buckley with lies is a scumbag.
2 Today's jobs report shows that the Trump economic plan is working: 119,000 new jobs when economists thought we would only add 52,000.Wages are continuing to outpace inflation and manufacturing hours are increasing. We've got a lot more work to do, but these are great signs.
toxicity
1 0.65996873
2 0.0101785113.3 Example: Census API
As another example of an API, the U.S. Census has an API that allows researchers to extract nicely formatted data summaries of different geographic units (e.g., all zip codes in the U.S.).
- Researchers can sign up here for an API “key” which allows the organization to monitor who is accessing what information.
Researchers Kyle Walker and Matt Herman have made an R package that makes working with the API easier.
- Example:
tidycensusfound here allows you to search Census data by providing the variables you want to extract
APIs can make a social scientist’s life easier by providing an efficient way to collect data. Without an API, researchers might have to resort to manually extracting information from online or writing an ad hoc set of code to “scrape” the information off of websites. This can be time consuming, against an organization or company’s policy, or even impossible in some cases. APIs are powerful and efficient.
However, because researchers cannot control the API, the downside is at any given time, an organization could change or remove API access. Researchers might also not have the full details of what information is included in the API, potentially leading to biased conclusions from the data. APIs are great, but we should use them with caution.
13.3.1 Using the tidycensus
install.packages("tidycensus", dependencies=T)Load the package
library(tidycensus)
library(tidyverse)── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ forcats 1.0.0 ✔ readr 2.1.5
✔ ggplot2 3.5.2 ✔ stringr 1.6.0
✔ lubridate 1.9.4 ✔ tibble 3.3.0
✔ purrr 1.2.0 ✔ tidyr 1.3.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsAdd your personal API KEY. Treat this like a password, and do not share
census_api_key("YOUR API KEY GOES HERE")Search for the variables you are interested in by loading a dataframe relevant to your research question.
## Load variables associated with Census/ACS/ACS-5
v23 <- load_variables(2023, "acs5", cache = TRUE)Extract data for the variable. We will extract the median income for NJ counties.
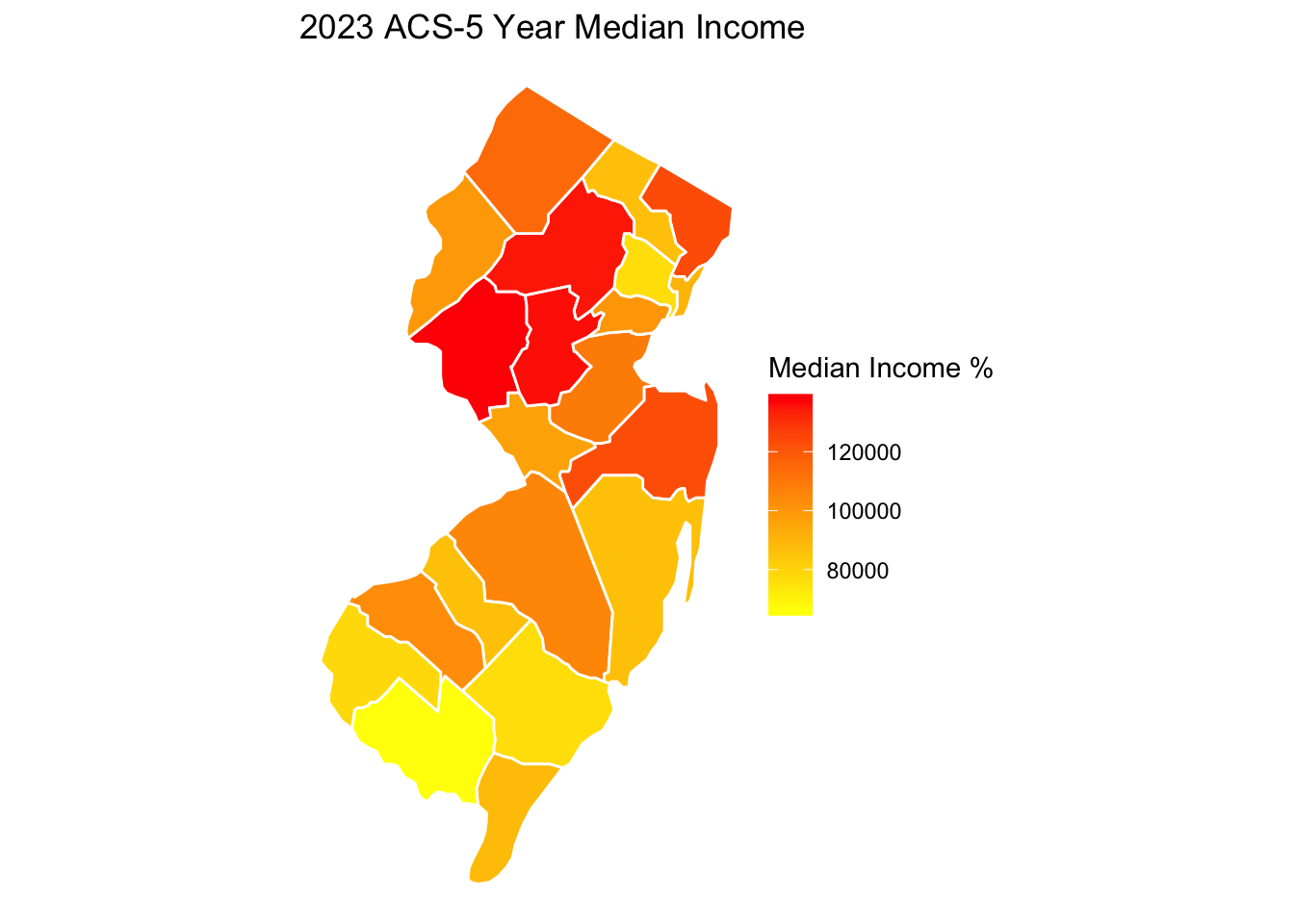
## Getting median income across NJ counties
nj <- get_acs(geography = "county",
variables = c(medincome = "B19013_001"),
state = "NJ",
year = 2023)njWe can save the data to our computer.
save(nj, file="njmedincome.RData")What can we do with this dataset? Analyze it or merge it with other data to anaalyze!
14 Preview of mapping in R
For example, to preview our next section, we can map the median income across counties in NJ.
## Load income data
load("njmedincome.RData")
## Load mapping package in R
library(maps)
Attaching package: 'maps'The following object is masked from 'package:purrr':
map## create a map of NJ
map(database="county", regions = "New Jersey")
Work to merge mapping and income data together (any outside data)
## extract mapping data
njcounties <- map_data("county", region="New Jersey")
## clean income data to match mapping data
nj$NAME <- gsub(" County, New Jersey", "", nj$NAME)
nj$NAME <- tolower(nj$NAME)
## merge the data
njcounties <- merge(njcounties, nj,
by.x="subregion", by.y = "NAME",
all.x=TRUE, all.y=F)Use ggplot to help map the data
library(ggplot2)
ggplot()+
## create an nj county-level plot
geom_polygon(data=njcounties, aes(x=long, y=lat,
group=group,
fill=estimate),
colour="white")+
## Shade the map according to the vote share
scale_fill_gradient(name="Median Income %", low="yellow", high="red")+
## remove background
theme_void()+
ggtitle("2023 ACS-5 Year Median Income")+
coord_quickmap()